2022黑马数据湖架构开发Hudi
2022黑马数据湖架构开发Hudi
智汇君2022黑马数据湖架构开发Hudi
基础入门篇 1
课程内容大纲和学习目标
1 |
1 |
为什么要学习Apache Hudi
什么是数据湖DataLake
数据仓库和数据湖区别
三大流式数据湖框架
Hudi 框架基本介绍
Hudi 快速发展
Hudi 快速体验使用
编译Hudi 源码
1 | 他这种编译方式,hudi0.9 如果自己使用的hadoop3系列会出问题,编译就通不过。不过他这里是先安装的hudi,其它的还没安装,所以不会使用到已有的一些依赖。 |
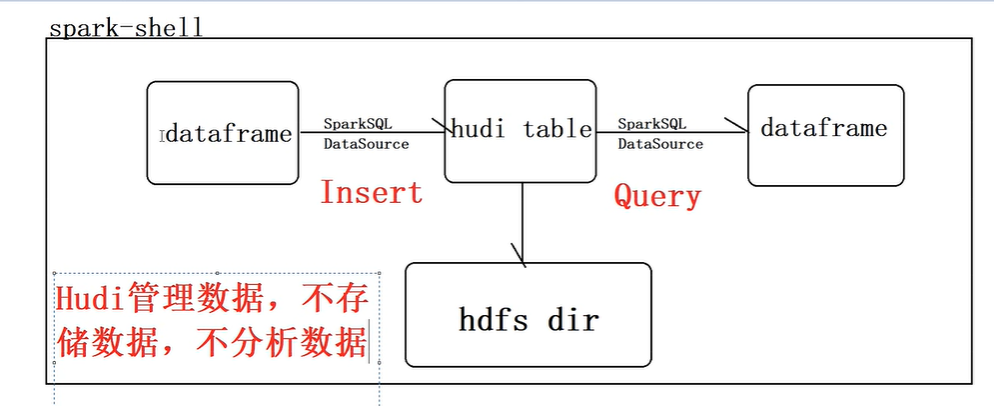
1 | OK,接下来呢,我们来看第二部分就是hudi呢,快速的一个体验使用,那说白了我们就是让hudi帮我们管理数据啊,哎,我们看一下怎么去用互理。那我们分为下面5个部分去讲,首先我们思考一个问题,在前面我们讲过,hudi,它是一个数据湖的框架,它就是管理数据的,它不存储数据,也不呢进行分析数据,那他既然不存储数据的话呢,那我们的数据,它管理的数据,我们需要有个地方怎么样进行存储。那在这里面呢,我们就使用我们讲的最典型的一个文件系统,就是HDFS。那所以说我们当hudi管理数据以后,我们需要去分析它的管理的数据,我们就需要计算引擎,比如我们把数据写到hudi表中去,以及从hudi表中呢加载数据进行分析,这时候呢,我们可以用我们讲的Spark和flink。 |
大数据环境准备概述
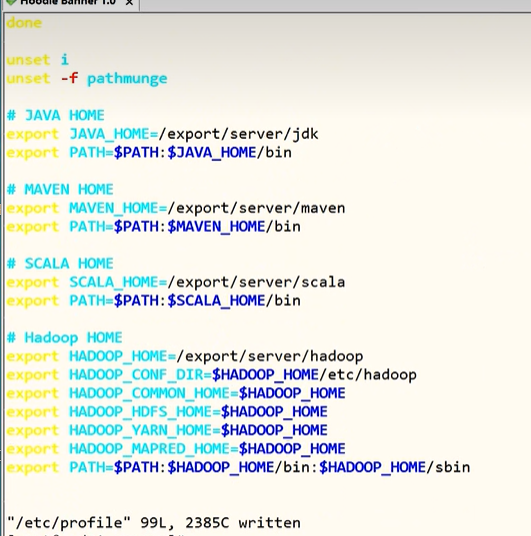
1 | 前面呢,我们把hudi编译好了,接下来我们要使用hudi,那使用的话呢,我们得明确一件事情,我们说hudi呢,它是一个数据弧的一个框架,它是管理数据不存储以及不处理数据,那这时候呢,我们需要做两个东西准备两个东西,第一个。hudi管理的数据,我们给它存到哪里去呢?在这里面我们选择了HDFS分布式文件系统,我们把它存到HDFS文件系统上去,那这里呢,我们就需要去安装一个HDFS文件系统,比说白了就是hadoop,在这里面我们使用的是hadoop3,我们也需要简单的安装一下。 |
HDFS 安装部署测试

1 | (坑壁这里hadoop用的2.7.3,hadoop默认支持的2点几的版本,hive也是2.几) |
Spark安装部署测试
1 | 前面呢,我们安装好了HDFS互地表的数据有存储的地方了,接下来呢,我们安装一个Spark。那我们要对hudi表的数据进行操作好,那这个安装也是比较简单的,咱们的Spark呢,我们就运行在本地模式就可以了,我们也不运行在这个什么yarn集群上面了。 |
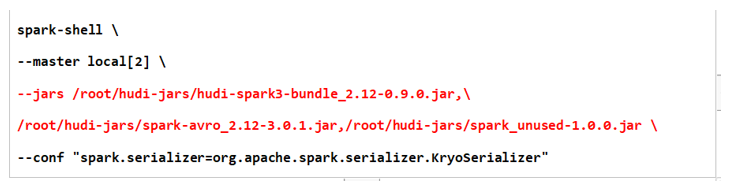
启动spark-shell添加jar包
1 | 他这里--packages下载到本地的其实有3个jar包,所以下面jars指定了3个 |


1 | 前面呢,我们把HDFS和Spark都安装测试完成了,接下来呢,我们要进行操作了。我们用Spark来操作我们hudi表的数据,那在这里面呢,我们首先用Spark提供的这个Spark shell命令行我们来进行操作。那我们看我们的需求。哎,我们首先以本地模式去启动Spark-shell命令行,在这里面呢,我们直接调用Spark官方给我们提供的这个工具类,模拟产生我们乘车的交易数据。啊,我们封装成dataframe.那然后呢,我们把data frame呢,给它保存到我们hudi表中去。最后呢,我们从hudi表中呢进行查询来读取数据。好,那这时候我们可以看到我们的护理的数据最终是放在HDFS系统上的。 |
1 | 那第二种方式呢,其实我们可以把上面的3个jar包呢,给它下载下来 |
基于IDEA编程使用Hudi
构建Maven模块环境
1 | 那我们在Spark消命令行呢,带大家呢去体验一下hudi啊,那其实就是帮助我们去管理数据,对吧?我们通过Spark把数据写到hudi表中去,以及呢,通过Spark从hudi表读数据,好那接下来呢,我们在我们的idea。这个开发工具当中呢,我们来进行编程开发啊,那我们呢,不仅是保存数据,查询数据,那我们还干嘛呢,去更新删除以及增量查询数据,让大家呢来体验一下,OK,那接下来呢,我们首先我们做第一个概念,我们要去创建一个maven工程。groupid cn.itcast.hudi |
1 | 那在这里呢,同学们就可以看到一个最基本的一个现象了,那这样的话就很简单了啊,因为那我们要做一些事情,我们是把数据存到我们的hudi表,hudi的数据呢,最终存在hdfs所以这里面我们需要把我们这个HDFS的一个配置文件,一个叫做core-site.xml,一个叫做hdfs-site.xml呢,给它放到我们resource里面去(main里的resource),让它能够读取到啊。好,然后呢,还有这个文件读进去。好,此外呢,因为我们开发程序的时候呢,可能有很多日志,我们也需要做一些事情,把Spark的这个配置文件spark conf里的log4j也给他拖进来。 |









