尚硅谷大数据技术之数据湖Hudi-2
尚硅谷大数据技术之数据湖Hudi-2
智汇君尚硅谷大数据技术之数据湖Hudi-2
核心概念
基本概念
时间轴TimeLine
文件布局File Layout
存储方式
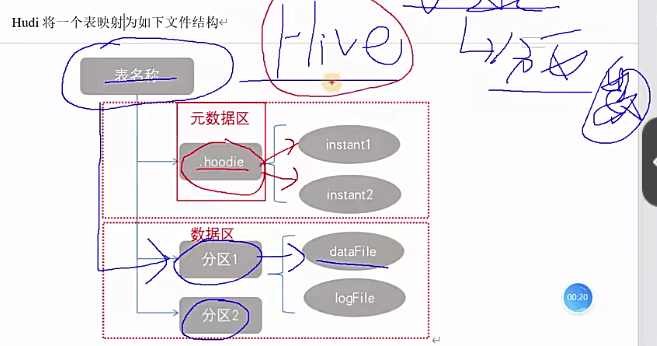
1 | 接下来看一下hudi的文件布局啊,什么意思呢?也就是说hudi它在存储系统上面,它是怎么一个表现形式啊,说白了,比如说咱们用HDFS作为它的数据存储的话啊,它以什么样的格式,什么样的目录来存储对应的数据,还有原数据啊,那其实这个这个地方我们可以类比为hive表。Hive的话,它一张表对应HDFS是不是一个目录啊,对吧?那目录名就是表名,那我们知道hive是不是可以有分区,它在表明目录下面是不是还有分区目录,那在分区目录当中存放的是不是就是数据文件,这个是hive对不对啊 |
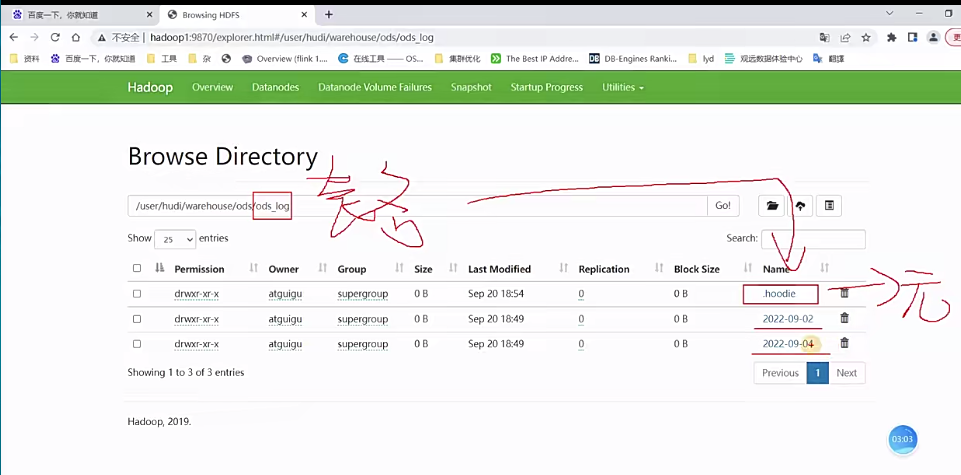
1 | 行,那可能简单这么一说大家应该都明白,接下来给大家看一个呃,实际的例子啊,那这边我已经启动了我的hudi的集群,那大家看看我之前跑过的一个hudi表就可以了啊,现在大家应该还没跑啊,但是大家先搂一眼吧,这是我之前跑的,呃,随便找一张表,那么大家看一下这个是我的路径而已。那接下来这些是什么表明,这是忽底表的表明了,跟hive一样啊,那我随便点一张表啊,比如说OdS_log,好,这个就是忽hudi的表名路径,在这个路径下面大家可以看到有什么一个.hoodie,这个就是所谓的原数据,那后面这些呢,是有我这张表是按照天来做一个分区的啊,所以大家可以看到它的分区目录名啊,就是某年某月某日,那我们呃,来点一下数据的分区来点。 |
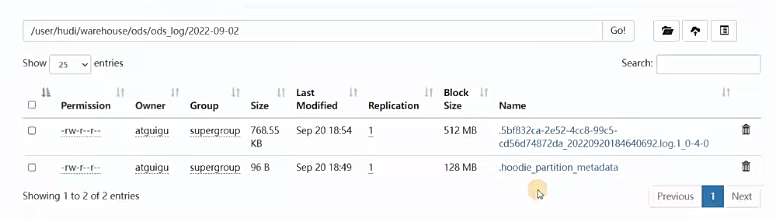
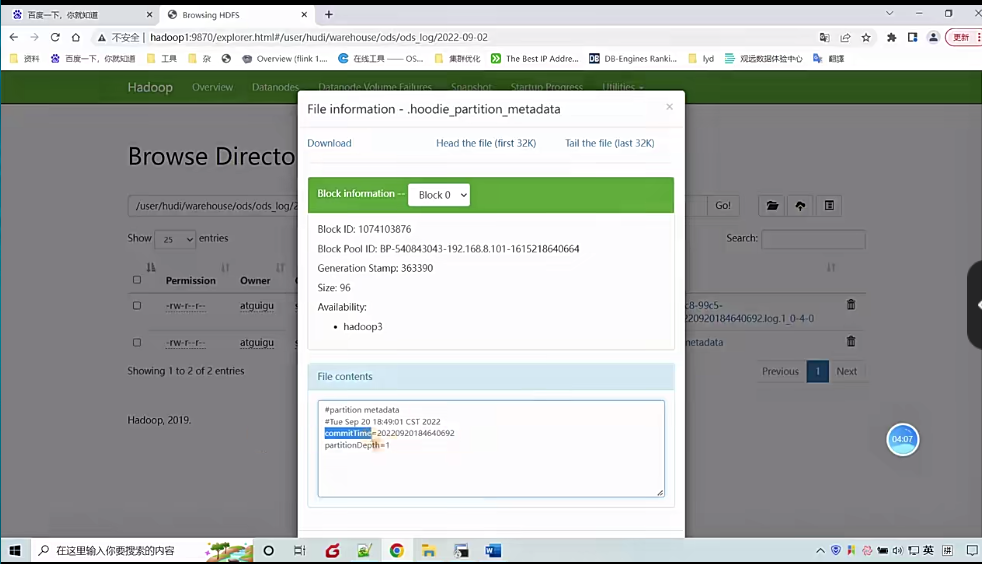
1 | 那除此之外大家看看是不是还有一个东西,这个不是目录了,你看它不是目录啊,它是个文件啊,每个分区它还有一个原数据文件来点一下啊,我们看一下它里面很简单,就是什么呢?有一个commit time,说白了就是这个分区路径创建的时间,时间戳啊,它是一串数字,是年月日10分秒啊,你看2022年9月20号18:46:40 692ms啊,这个是精确到毫秒是不是啊,然后还有一个什么分区的深度,也就是说你分区路径下还可以有啊其他分区。就多级分区这种样子了,现在我是一级分区,所以它的深度只有什么1啊好,那这个点log其实是数据文件,你看我点一下你看。在这边就能看到一些数据了啊。这是数据啊,阿波罗格式的,行,这个简单搂眼啊,另外一个分区也一样啊。 |
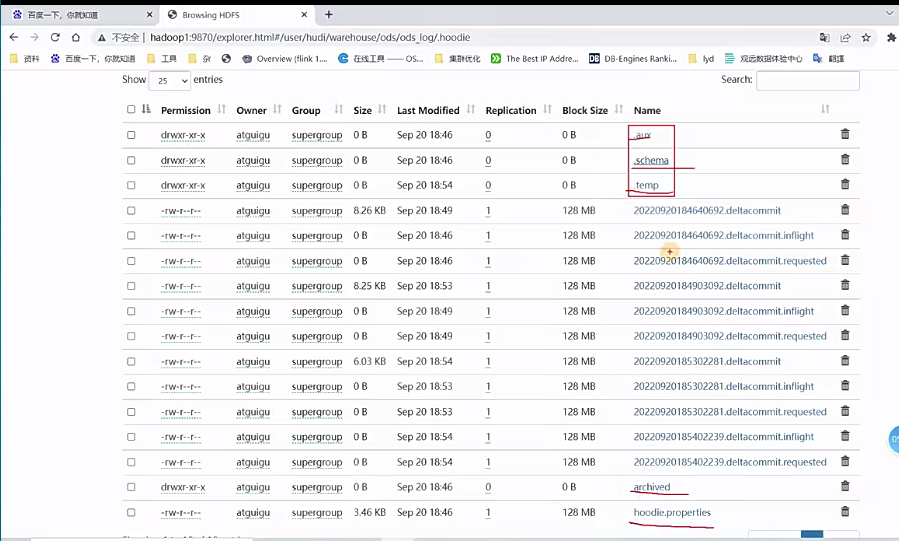
1 | 接下来我们搂眼这个原数据目录啊,点.hoodie。好点一下进来之后啊,我先刷新一下,那么大家在这里可以看到一些文件啊,首先是一个点开头的啊,它会自己会用的一些东西,对吧?像什么schema,还有临时目录temp啊这些东西,还有归档archieve啊,hudi配置啊这些 |
文件管理
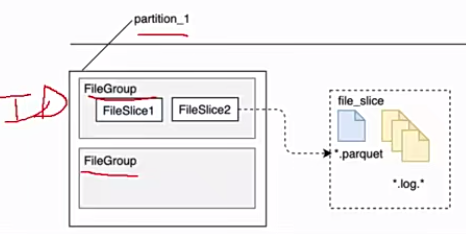
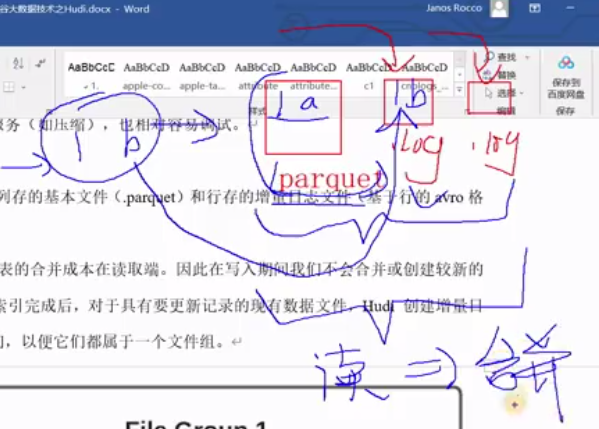
1 | 那么这个文件布局当中,我们还要了解一个他对文件的一个管理。因为我们知道hudi前面也聊了一些特性,它支持那个呃版本控制,然后呢又可以去做一些compassion,对吧?那这个时候就注意新版本跟老版本文件的一个问题了。那我们先了解一个概念啊,看这张图呃,这个是一个分区路径啊,大家注意啊,外面这个大黑框表示的是某一个分区的护底表的某一个分区目录了。在一个分区当中,刚才带大家看的是不是有.log文件了啊,其实也有可能有点.parquet文件是吧?好,那他还做了一件事,他将这些parquet跟log封装成一个一个的,也不是封装了啊,就是划分为一个一个的文件组。大家注意叫文件组file group。那每一为什么叫group呢?因为它每一个组里面存储了多个文件片,每一个文件片代表一个版本,能理解吧?啊,比如说file slice1啊,这是老版本,file slice2就是现在目前最新的版本。 |
1 | 好。另外注意一个事啊,那我们先来聊一下parquet的文件的一些细节。这个基本文件它在里面的footer的meta里面是记录了什么record key,它里面用的是布隆过滤bloomfilter。说白了就是有一个索引,同学们啊有一个索引。嗯,他这样通过这个东西就能高效的去检测这个record key在不在啊,只有不在的时候才去呃需要去扫描整个文件,去消灭假阳性。我们知道布隆过滤是不是有假阳性啊,假阳性就是说布隆过滤这种实现方式,我们只能百分百确定啊不存在。但是如果不能过滤显示存在,那是不是也有可能它不存在,对吧?有个假阳性率,或者咱们直白大白话来讲,就是有一个准确率的问题。你说不在那就一定不在,但是你说在那只能说可能在能理解这个意思吧,因为你说在是有准确率的。啊,这个布隆过滤呃,自个去了解吧,它就有一个哈希函数,还有多个哈希函数,哎,还有K值啊,怎么样去计算?嗯,呃总而言之,这一段话什么意思呢?也就是说呃这个parket里面它记录了每一条数据的一个唯一key,叫record key。啊,这个词大家稍微记一下啊,会经常提到,经常用到啊。举个例子啊,我有张表啊,别管分不分区呢,比如说我有数据123啊1A2B3C这么三条数据吧。啊那假那么这三条数据刚好就在一个parquet文件里面啊啊,就别说刚好就是在一个parquet文件里面。这个时候呢其实呃这个Parquet文件会记录一个索引index。那我们可以基于布隆来做这个索引的查找。因为布隆布隆会快一点,并且节省空间嘛,效率高嘛,是不是啊?布隆过滤。那这个时候呢哎比如说我现在要呃更新或者插入,这个时候你是不是得嗯先判断一下相同key的在不在。这个key是由咱们去呃可以由我们去指定的啊,就是这个key啊,比如说1A这个key,我用第一列作为key,也就是说第一行的key是1,第二行key是2。 |
1 | 好,再看下一点hudi的log,也就是点log这种后缀的是avro的编码,对吧?他通过积攒buffer,并且以log block为单位写出。也就是说他并不是一条一条写的,就想说这一点而已,而是攒一批数据咱们去写一次log。那每一个呃log block一个文件,一个日志快吧啊,咱们叫log快吧。有一个魔法值magic number,大小size、上下文content,呃文本,还有一个footer等信息用于数据读、校验和过滤。当然这些事不需要我们去关心啊,这是他内部实现的一个机制,对吧?但是既然聊到就简单说一句 |
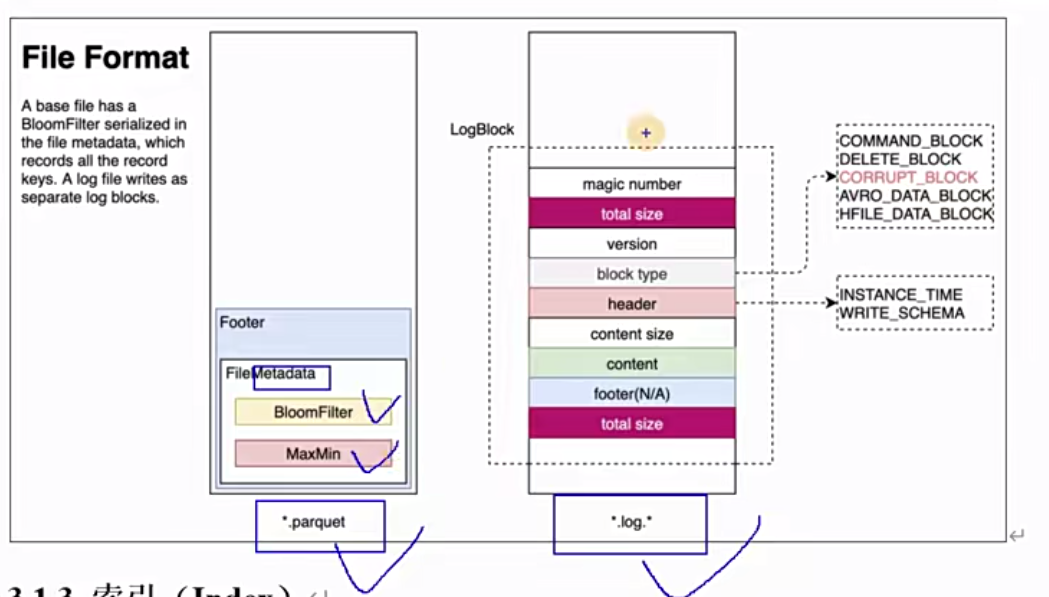
1 | 那下面这张图就很明显了,这是两种格式的文件,一种是parquet,一种是log。那parquet文件重要特性就是会做一个什么呃,文件的原数据里面会有一个索引啊,可以用布隆,可以用其他的索引方式。那log就更复杂了,对吧?他记录了一堆东西。好,这个是文件布局。 |
索引
原理

1 | 那刚才也聊到了一个关于索引,对吧?那现在咱我们就来好好聊聊这个索引的一个东西。那一开始也介绍了hudi啊通过索引机制提供高效的upsert。那接下来问题就来,我是怎么来高效的啊,其实前面也简单讲过了啊,它具体是给定一个东西叫hoodiekey对吧?一个key那它是由什么组成呢?一个叫record key记录键对吧?Record就代表你数据的一条一条的记录,就叫record key啊。然后加上什么呢?分区路径partitionpath。大家注意这两个东西组起来叫hooodie key,它与文件ID那么刚才聊到了文件ID是什么?一个文件组有一个唯一的文件ID啊,记住了。好,那也就hooodie key跟文件ID建立了一个唯一的映射。这种映射关系第一次写入文件后保持不变。大家注意第一次写入文件后保持不变这句话什么意思?也就是说这就代表这个映射关系是固定的,是唯一的啊,就这个意思啊,所以呢一个文件组包含了一批数据的所有版本记录啊,我这个前面也聊了对吧?啊,有点拗口。但是我们具体解读就是什么呢?一个文件组里面有多个文件片,每一个文件片都是不同的,是呃不同的版本,对不不对啊, |
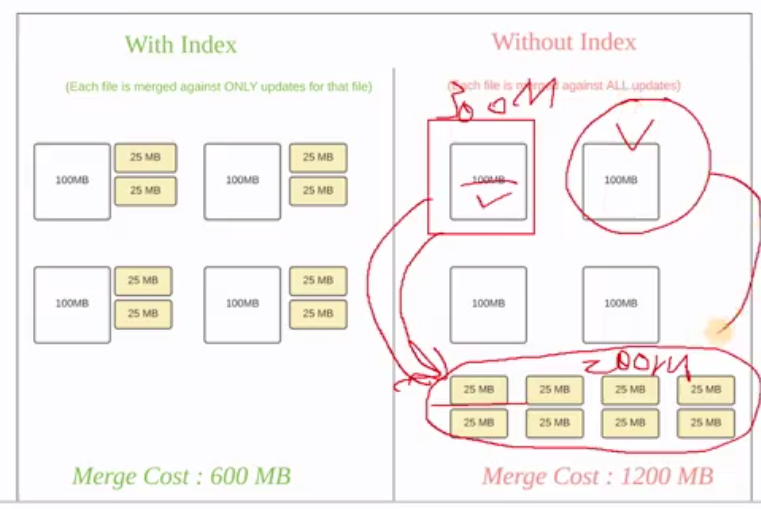
1 | 那下面是官网给出的例子啊,这个索引有什么用啊?再进一步理解一下,hudi为了消除不必要的读写,引入了索引。有了索引之后,更新的数据可以快速被定位到对应的file group。因为我们前面也聊到了,就是它这个索引是不是hoodiekey跟file group那个文件ID的绑定,对吧?直接看图吧,白色的是基本文件,也就是parquet,黄黄色是更数数据,先别管什么parquet .log了,反正就是这是现现有的数据。呃,然后黄色是后面新过来的数据啊,可能是插入,可能是更新,对吧?那如果有了索引什么意思呢?我们一共有几个?123456788份这个更新的数据,每一个是25兆。啊,那这个时候呢呃比如说你如果没有索引,大家想一想,比如说就看这个就好了。这个25兆的文件我怎么知道我要往哪一个方去更新呢?你是不是所有的地方都得干嘛都得去扫描一遍,是不是扫描一下,你这样全量扫描,扫描一下你的这些数据是该往哪里去写,去往哪里更新,效率特别低。但是如果有了索引,这25兆是不是就知道哎他要更新的东西在哪,哎,就是这一百兆对吧?另外这是另外的25兆的更新数据,他是不是就知道他对应的呃数据在这100兆里面。我举个例子啊,这100兆里面有123,那这25兆里面就有一的更新,二的更新,对吧?那这一百兆是456,那这这黄色的这个里面是五要更新对吧?那你看嘛它要更新的是5。他是不是找到无所在的基本文件就行了,他不用所有的基本文件都去扫一遍,能理解这意思吧?也就是说他知道他的目标在哪,这样的话他我们的合并开销是多少啊啊你看这一边呢是100呃加2个25,这个是不150对吧?这是四个文件组嘛,呃那这样的话我们合起来是不是开销就是600 150乘以4嘛,对不对?这个很好理解对不对?这个是大家都知道你要的对象在哪里,对吧?目标很明确,那你就开销少好另外一种没有缩音的时候,这是原先来四个基本文件啊,四个基本文件在这摆着啊,有400兆的数据,然后呢有八次的更新,每一次二十五兆。那现在问题就来了,这25兆他知道要去找谁吗?他不知道吧。所以你这一百兆的是不是要每一个基本文件是不是都要跟所有的更新数据做一次匹配啊?对不对?那这个时候你看它开销是多少,每100兆就得跟这些25兆有八个,这边合起来是200对吧?他是不是要扫描200兆的数据,哎,然后把属于自己更新的部分摘过来。所以它的一次开销是多少?100加200,他自己100嘛,所有的增呃更新是200嘛,加起来是不是300对吧?好,那下一个基本文件,100兆的数据它也一样,它是不是也要在这200兆里面找到属于自己的更新数据,它的开销是不是也是300兆?好,那这四个基本文件这么一下呢,它的开销是多少?1200兆,那你看这个差距是不是差了一倍啊? |
索引选项
1 | 那理解完索引的基本原理,接下来我们聊聊细节了,呃,那是从索引的作用来讲,那么接下来忽底它支持哪一些索引的类型,说白了也就是索引的实现方案,实现方式 |
全局索引与非全局索引
1 | 在hudi的索引当中啊,它又区分了全局索引还有非全局索引。那所谓的全局索引呢就是整张表而言建立的索引。也就是说即使你做了分区,那么我是整个所有的分区一起来看,那每一个key啊也就是那个所谓的record key啊,数据键它是唯一的,不会有重复的。即使你的数据是在不同的分区,那我也不允许你有重复的这个键啊,那这样就能够确保给定的一个键只有一个对应的记录整张表的范围内。但是这也有一个很明显的缺点呢,如果我这张表特别大,那大的你受得了吗?对吧?那你随着你咱们表的数据量越来越大,你去做一个更新删除操作的时候,你这个性能就越差,对吧?因为你要全表的去匹配,那这样的话即使你做了索引,但这样效率也高不了。所以这种全局索引呢更适合用于小表啊,就是表的数据量并不大,那其实用全局索引呃比较理想。 |
索引选择策略
对事实表的延迟更新
1 | 那么接下来就是我们这么多个索引怎么来选择呢?或者说什么样的场景更适合什么样的索引。这个那么下面给到大家的是官方的一个资料啊,这个描述也好,这个动图也好,都是官方做的那我们一起来看一下,第一个场景是对事实表的延迟更新,什么意思呢?呃,熟悉数仓建模理论呢,我们都知道我们通常会去构建一些事实表还有维度表。对吧那对应呢我们会去构造各种模型,像什么新型模型、雪花模型、星座模型,这是基于维度建模理论。总而言之呢,我们通常在数仓里面都会有一个事实表和维度表。那事实表其实就是对应我们的业务过程。那比如说你如果你是电商场景,那你应该就有大量的交易。比如说订单的数据,支付的数据啊,还有比如说像什么加购物车的数据,这种都是属于咱们的事实数据。那这一些呢,我们通常首先会在数据库当中存储大量的这些事实的交易数据,对吧?那除了电商场景,还有其他的像共享出行的什么行程表,股票买卖记录表啊,这都是不同业务场景下的一些事实表啊,电商的订单表。呃,那事实表有个特点就是什么呢?啊,随着你的业务在不断的就用户在使用啊,不断的操作,不断的去执行一些业务过程。那么你事实表的数据应该是一直在不断的增长。就比如说订单好了,你每天都有人下单,那你这个订单的数据应该是越来越大越来越大。啊。另外呢这些事实数据还可能发生什么呢?更新更新。而且更新的话我们还要考虑一个事情,它更新的数据大概呢是很久以前的,还是说最近的呢?那么大家可以想一想,比如说电商的订单表就好了,一笔订单的状态要发生改变对吧?啊,比如说咱们退单呢,或者从下单变为支付状态啊,或者再再到最后的呃签收状态等等。这些看你业务怎么定义啊。呃这些是不是针对于最近的这些订单才有可能啊,比如说你距间隔了一个月以上,那么你这个订单的信息是不是基本上不会再变了。因为从业务上来讲,商家也不会再允许你超过一个月再去说做一些退单,或者说我下完单一个月不不付款,一个月后再付款,这种应该是不会出现,对吧?所以呢这种更新事实数据的更新应该是发生在什么较新的记录上。也就是说它的更新数据分布是有特点的啊,都是最近的。那么对于比较老的一些数据呃,它的更新就比较少了啊,因为这一笔订单,这笔交易早就关闭了啊,不会再变更了啊。 |
1 | 那这个时候我们就希望呃布隆过滤器的一些参数啊,一些一些变量能够动态的调整。可以啊,我们只需要什么设置这个参数就可以了hoodie.bloom.index.filter.type=DYNAMIC_V0。你看啊hudi布隆首先指定为布隆索引的过滤类型,指定为动态的,就可以指定为动态。它可以根据咱们总的数据量来调整布隆相关的一些参数,而从而达到我们希望的那个假阳性率。啊,或者既然说到这儿,我就简单给大家看一眼吧。呃因为有的人可能还不太熟啊,不太熟啊啊比如说布隆,你搜一下过滤器。呃,我看一下有没有原理的介绍啊,看一下10分钟理解啊,随便找一篇啊,我只想找到它的公式,原理我就不讲了啊,原理不讲了。这篇没有给我们那个数学公式啊。啊,随便点啊。呃,这个也算吧,但我想找一篇更全的。哎,你看啊呃,那我们看也就是说跟公式有关系啊。看这一篇。哎,详解布隆过滤器的原理、使用场景、注意事项。我看一下这个的。好,那我们看一下啊,也就是说这些公式大家自己看一看就行了。它有我们的数据量啊,其中一个参数,数据量一个是K值,一个是M值,一个是bit map的大小。这一节能够计算出一个一个它的阳性率啊,或者说准确率,或者也可以算为什么误报率。 |
对事件表的去重
1 | 好,第二种场景是对于事件表的去重大家注意是事件啊,不是事实事件是什么呢?比如说前端买点产生的这些呃事件流。比如说呃点击流,用户的点击买点产生的数据,还有咱们物联网,比如说车联网一些传感器产生的这个数据啊,我们通常称为事件流嘛对吧?还有广告点击这些啊广告曝光。好,那么这一些呢我们通常会将这个数据先采集进kafka对吧,这种消息队列。那么而且这种的数据量一般呢是咱们业务数据库当中呃10到100倍,也就是说事件事件的数据往往是大于事实的数据,对吧?也就是说数据库里的数据跟我埋点产生的数据哪个更多呢?一般来讲是买点还有传感器产生的这种啊会更多一点。而且他有一个特点,他要不要更新呢?这种事件的数据一般而言都是追加啊,不存在更新。大部分而言啊,那即使有更新,那可能也是最近的几个。那这个时候呃涉及到一个数据重放啊,可能是一个采集的一致性这些问题可能有一个重复的问题。那这个时候去重也是一个很常见的一个需求吧,对吧?这个大家做过的话应该都很熟悉啊,不管你是什么业务场景。 |
对维度表的随机更删
1 | 那么对维度表的随机更新和删除,什么叫维度表啊?像什么地区啊、时间呢呃渠道啊对吧?这一些就是我们所谓的维度。比如说你电商场景是不是还有呃商品维度对吧,是哪一个品类的啊等等这一些。包括什么用户维度表对吧?记录了用户信息的这些表啊。用户维度信息也就是说你在建模的时候肯定要去构建一些维度表。那维度表有个特点啊,它的更新和删除。我举个例子,一张用户表啊,比如说你有张用户表,呃,有123有3名用户啊。用户一是去年创建的啊注册的啊用户二是今年呃上半年注册的用户,三是现在注册的。那这个时候呢呃很久以前注册的一他有没有可能更改信息啊?很有可能吧,他可以更改他的呃绑定邮箱,更改他的绑定手机号,可以更改昵称,可以更改地址,是不是都可以改,对吧?也就是说你并不是说你的更新都集中在最近这一段时间,而是不一定啊,所以我们叫随机啊随机。 |
表类型
COW表
1 | 前面聊了这么多概念,那么接下来这个概念是大家必须要了解的。就是表类型在hudi当中它有两种表,一种叫copy on write,简单来讲就是写实拷贝。另外一种表呢叫做merge on read,叫读实合并啊,那么大家记住啊,这是物体特有的两种表类型。 |

1 | 这也是为什么叫写时拷贝,拷贝的是什么呢?拷贝的是原先的parquet文件,将原先parquet文件都拷过来,再将新增的部分及变化的部分合并进去,再写入一个新的文件。那新的文件它也是一个parquet。那这个时候呢对应我们前面聊到的一个概念叫什么呢?文件片。那这个一二三这个比如说它就是一个文件片啊,比如说是一吧,我们称之为一fileslice1。那么写示拷贝完啊合并完这个新的parquet文件,那可能我们就可以认为它是一个文件片fileslice2,它们都是在同一个文件组里面是吧?嗯,这也是为什么我们前面说到这个文件片,可以理解为呃不同文件片是不同的数据版本。好,这简单理解啊呃新版本文件包含旧的文件记录集这个批次的记录,那最新的这个文件片就是包含了全量最新的数据了。 |
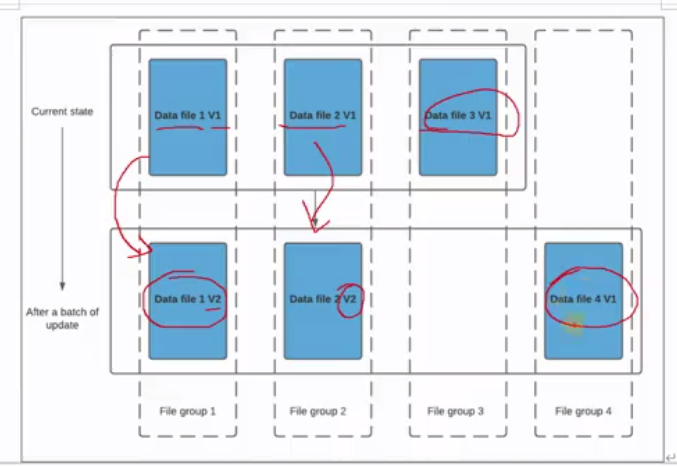
1 | 好,那下面看一个具体的例子啊,其实大家基本理解了啊,那当前呢是给到3个file group。有三个文件组。那么目前呢他们的版本都是第一个版本啊第一个版本。好,那这个时候我们进行一个数据的写入,新的写入。那你看啊场景是这样,在索引之后我们发现这些记录与啊文件组一、文件组二匹配了。也就是说什么呢?啊,我有一些数据是要属于更新操作的啊,那这些数据对应的原先数据在文件组一和文件组二里面啊,另另外呢有一些数据它是属于新的插入啊,不是更新啊啊那个时候候我会将将的插入入写到一个新的文组组,也就第四个组。比如说啊好,所以就变成下图这样子,文件组一、文件组二有些数据需要更新啊,那这个时候他们就会对呃旧的呃V一版本的数据,还有更新的数据进行合并啊,并且呢写入一个新的parket,生成了一个V2版本。那文件组2同样的道理,它也生成了一个V2版本,新的文件片,新的parquet,那文件组三呢没有变化啊,那还有一些是新插入的数据啊,就写入一个新的文件组。文件组四好,知道这个应该都好理解吧。 |
MOR表
1 | 接下来我们看第二种类型的表,merge on read, 也就是所谓的读实合并。那么大家注意它包含什么样的文件呢?第一,它可能有parquet文件,大家注意我的描述啊,可能有parquet文件。另外它一定会有一个基于行存的增量日志文件,也就是avro格式的。那么它具体的文件名呢,就会看到点log这么一个后缀啊,这个我们前面也是简单给大家看过,对吧?有一些点log。好,那为什么叫MOR呢?那是因为它的合并在读取端,什么意思呢?哎,你看我现在是不是既有这个基本的列存文件parquet。另外呢还有每一次呃新增加的数据,比如说插入或者更新的数据,它这一批数据会记录在一个点log文件,对吧?那再来一个新批次,又这些数据又有插入有更新,它可能又在一个新的点log文件。也就是说在这张MOR表当中,他是不是可能有parquet,又有多个log,那你读的时候该怎么读啊?因为老的parquet文件,它里面可能包含了一些是过期的数据,对吧?啊,比如说我们原先这里有一条1A这么一条数据,然后后面我对它进行了呃更新。那我是不是有一条数据,比如说A变成B啊变成一B啊,这是更新后的数据。那它过来它不会对原先parquet文件进行处理,而是什么呢?将这一条更新的数据放在点log文件,对吧?所以这个时候如果你只读这个parquet那可能是不准的。所以你要综合parque和点log文件啊,才能得到最新的结果。 |
1 | 这个MOR表读的时候parquet也好,log也好,它都会一起在读的时候进行合并。这也是为什么叫读时合并啊,只有在我进行读取操作的时候,我才会将parquet跟log进行一个合并。好。所以它的合并在读取端啊,它而且呢它在写入的时候不会进行合并或者说创建新的数据文件,对吧?这个就区别于COW表,它是写入的时候进行合并生成新的文件啊,那MOR不会也也就相当于说是反过来了 |
COW与MOR的对比
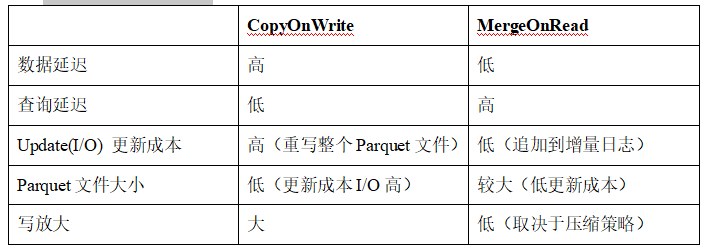
1 | 那接下来我们就来对比一下这两种表的优缺点啊区别在哪里啊。那我们看一个从数据的延迟来讲谁更高啊。COW更高一点啊,MOR的表反而会更低一点啊,数据的延迟。 |
查询类型(Query Types)
Snapshot Queries

1 | Hooody呢提供了三种不同的查询类型,我们一起来了解一下。第一种呢是快照查询。什么叫快照呢?简单来解就大家记住就是四个字叫全量最新。哎,我就要查询当前呃数据最新的一个状态,全量最新就记住这四个字就行了,这就是快照查询。 |
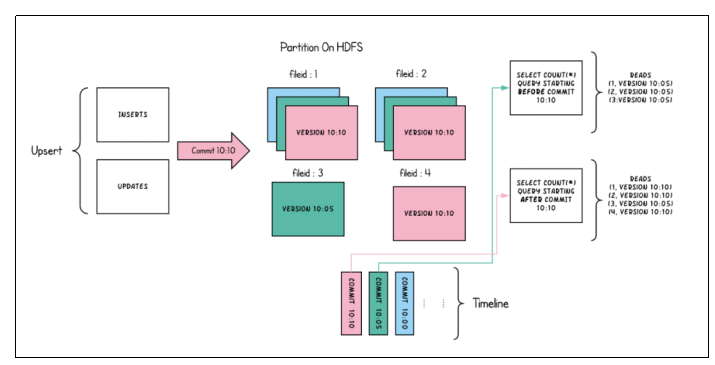
1 | 下面这张图简单搂一眼啊(COW快照查询),这什么意思呢?呃,大家注意看这边有四个什么呢文件组,这是file ID啊。它这个字体可能容易看错啊,这是file ID然后这是file ID1234表示四个文件组啊。另外呢就是呃这个是COW表为例啊,那我们看啊他在十点钟的时候啊,用这个淡蓝色表示进行了一次commit。那这个时候可能插入的呃只有两个文件组,文件组一还有文件组2,你看他们有蓝色的对吧?好,再之后呢在绿色的这个时刻,也就10点05分,呃,他又有一批新的数据commit了。那这个时候呢可能涉及到什么?呃,文件组一、文件组二里面数据的更新,还有呢一批数据的插入啊,也就是文件组三了啊,所以大家可以看到一二呢这里有更新,然后三呢是新插入。好,那么粉色的这个就10点10分的时候再一次commit一批数据,这个时候可能涉及到文件组一、文件组2的更新,对吧?啊,所以呢啊一二又更新了,然后呢又有一批数据新的插入啊,在文件组4。哎,在所以呢这个是一个不是一个动图啊,所以大家会看。那完事之后呢,我们可以看到你在10点05分的时候去查询它的全量最新快照是什么?你看在05分的时候,你进行一个快照查询,全量最新是什么?是不是文件组1二三里面的这三个parquet文件呢?对吧?啊,所以你看有文件组1二三里面呢,他们的版本都是5分的时候,这个时候文件组四还没有生成呢,还没有呢,能理解这个意思吧? |
Incremental Queries
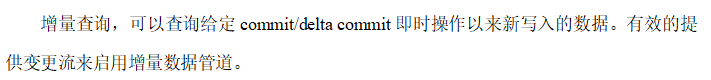
1 | 看增量查询,它可以查询给定的提交commit或者增量提交delta commit。这个提交就对应咱们那个COW表的方式啊,delta commit就是对应MOR表的这种方式啊,呃给定了这个某一次commit以来新写入的数据,对吧?就比如说刚才这个例子,如果现在时间已经到了,经过了10点10分的commit,呃,你可以怎么样呢?你可以指定说哎我从10点05分之后或者从十点钟之后以来先提交,而不用去查询这个commit之前的一些数据的啊。 |
Read Optimized Queries


1 | 还有一个叫读优化查询。大家看描述的话是commit还有compassion的最新快照。有的人就有疑问了,那这个跟快照查询不就一样吗?哎,大家注意咱们这边描述可不一样。普通的commit对应的是COW表啊,所以对于COW表来讲,快照查询跟读优化是一样的。但是对于MOR表来讲就不一样。这个delta commit,这个compassion也好,都是对于MOR而言的,对不对?读式合并,那delta commit呃就是增量提交。那我们知道呃增量提交完,然后你再去查这个快照查询一定是全量最新。但是compassion就不一定了。因为每次compassion之后,它是不是将老的parquet跟多个log进行一个合并,生成一个新的什么新的parquet是吧?那这个新生成的这个parquet一定是全量最新吗?不一定啊,为什么呢?我可能在compassion之后又进行了好几次的增量提交,又多了好几个.Log文件能理解吧?如果是读优化视图,它的区别在哪?它只会查询最新compparsion之后的这个parquet文件。也就是说在这一次parquet后面的这一些点log它查不到了啊,所以对于MOR来讲,它并不是全量最新能理解吧? |
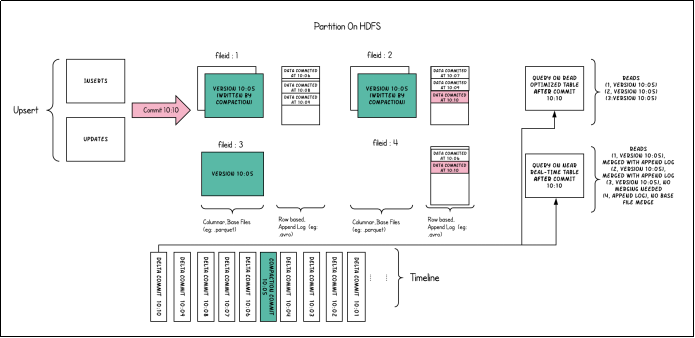
Read Optimized Queries是对Merge On Read表类型快照查询的优化
1 | 好,那下面有一个具体的对比啊,下面这张图就是对于MOR表而言,它的快照查询与读优化的一个对比。那么在呃从10点01分开始,差不多每1分钟进行了一次增量提交是吧?那么在10点05分的时候触发了一次compassion,大家注意compassion,那触发compassion之后有什么特点呢?就是会生成一个新的parquet文件,哎,那对应的是哪一个呢?哎,文件组一、文件组2、文件组3。在10点05分的时候,compassion之后生成的基本列文件啊用绿色表示。好,那我们接着往下看,在06分、07080910的时候分别进行的都是什么?增量提交增量提交每一次提交是不是生成一个点log文件,对吧?啊,所以你看对于文件组一来讲,它包含了呃06的点log、08点log、09点log。那对于文件组二呢,它有07的、有09的、有10的点log对吧?那对于文件组四三啊,压缩之后他没有新的数据来。文件组四一开始是没有的,但是在06分和10分的时候都是呃插入的数据嘛,相当于是对吧插入的新插入的数据。好,那这一块呢它就有一个点log,一个点log能理解吧? |

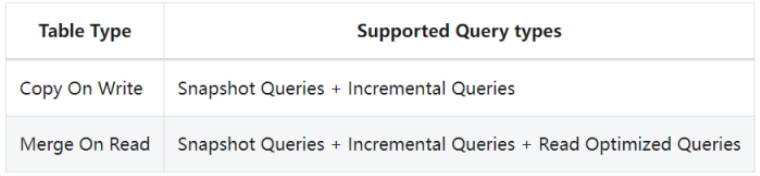
不同表支持的查询类型
1 | 那么看看不同的表支持的查询类型啊。其实对于COW表来讲呢呃就简单的两种。一个是全量最新的快照,还有增量两种查询。 |