面试 linux常识
面试 linux常识
智汇君linux常识
逻辑结构
条件判断
if elif else
1 | if [[ "$USER" == "lk" ]]; then |
1 | if [ 条件判断表达式 ];then |
1 | 注意事项: |
1 | [ condition ](注意 condition 前后要有空格) |
两个整数比较
1 | 比较运算符左右也要有空格 |
1 | = 字符串比较 |
1 | >>[ 23>22 ] 比较运算符左右也要有空格 |
1 | >>[ 23 -lt 22 ] |
1 | #!/bin/bash |
按照文件权限进行判断
1 | -r 有读的权限(read) |
1 | >>[ -w helloworld.sh ] |
按照文件类型进行判断
1 | -f 文件存在并且是一个常规的文件(fle) |
1 | 如何检查文件系统中是否存在某个文件 ? |
1 | >>[ -e ~/myshells/helloworld.sh ] |
判断字符串是否为空
1 | -n 字符串:检查字符串是否非空。 -z 字符串:检查字符串是否为空。 |
1 | if [ -n "Alice" ]; then |
[]和[[]]?
比较操作符
1 | 在 [[]] 中可以使用比较操作符,如 >、< 等,如下: |
对整数比较符
1 | 对整数比较符 -eq、-ne、-gt、-lt、-ge 和 -le,[] 和 [[]] 都可以正常比较,如下: |
布尔操作符
1 | 在 [[]] 中,我们可以使用逻辑运算 && 和 ||,如下: |
聚合表达式
1 | 在 [[]] 中,我们可以使用括号 () 来聚合多个表达式,() 的使用可以让脚本更具可读性,如下: |
模式匹配
1 | 在 [[]] 中,我们还可以使用通配符进行模式匹配,如下: |
正则表达式
1 | 正则表达式是另一种字符串模式匹配的方式,在 [[]] 中,我们可以使用正则表达式来做模式匹配的工作。 |
单词分割
1 | 在 [[]] 中,Bash 不会对值中的单词进行分割,比如变量的值是一个包含空格的字符串,Bash 不会将其分割成多个单词。 |
单中括号 []
1 | 单中括号是Shell内置命令 test 的另一种形式。它主要用于基本的字符串和数值比较。以下是一些关键点: |
双中括号 [[]]
1 | 双中括号是Shell的关键字,提供了更强大的功能和更灵活的语法。以下是一些关键点: |
使用建议
1 | 数值比较:使用单中括号 []。 |
case语句
1 | case $变量名 in |
1 | >>touch case.sh |
逻辑与逻辑或
1 | && 表示前一条命令执行成功时,才执行后一条命令 |
1 | >>[ xxxx ] && echo ok || echo "not ok" |
1 | >>[ xxxx ] $$ [] || echo "not ok" |
循环
for循环
1 | for((初始值;循环控制条件;变量变化)) |
1 | for 变量 in 值1 值2 值3... |
1 | #!/bin/bash |
1 | >>touch for.sh |
1 | for i in {1..254} |
1 | for i in $(seq -w 1 30) |
1 | for i in {0..100..3}; do echo $i; done |
1 | for i in /etc/profile.d/*.sh /etc/profile.d/sh.local ; do |
for in $* $@
1 | for in和$*和$@一起用 |
1 | >vim forin.sh |
1 | [root@bigdata02 myshells]# sh forin.sh 1 |
1 | for i in $(ls); do ... done 循环来遍历当前目录下的文件和目录是一个常见的做法 |
while循环
1 | while [ 条件表达式 ] |
1 | >>vi while.sh |
1 | 在 Bash 中,当你使用 let 命令来执行算术运算时,你不需要在变量名前加 $ 符号来引用变量的值 |
1 | #!/bin/bash |
until循环
1 | #!/bin/bash |
变量
1 | 打印变量 |
1 | 只读变量 readonly |
1 | 删除变量 unset |
1 | 环境变量 |
如何向连接两个字符串 ?
1 | V1="Hello" |
1 | greeting="Hello" |
1 | [root@bigdata01 ~]# A='A' |
1 | message="${greeting} ${name}" |
如何进行两个整数相加 ? 有点特别
1 | linux:~ # A=1 |
1 | linux:~ # A=1 |
1 | linux:~ # A=1 |
1 | linux:~ # A=1 |
‘ 和 “ 引号有什么区别 ?
1 | ' - 当我们不希望把变量转换为值的时候使用它。 |
如何只用 echo 命令获取字符串变量的一部分 ?
1 | echo ${variable:x:y} |
如何打印变量的最后 5 个字符 ?
1 | echo ${variable:-5} -前空格 |
如何获取变量长度 ?
1 | ${#variable} |
如何仅用 echo 命令替换部分字符串?
1 | echo ${变量//模式/替换} |
数组
1 | fruits=("apple" "banana" "cherry") |
shell传递参数
1 | 获取位置参数 |
1 | # 脚本名:special.sh |
1 | ./special.sh arg1 arg2 arg3 |
${1:-1}
1 | START_PART=${1:-1} |
如何在后台运行脚本 ?
1 | nohup command& |
重定向
> 和>> 输出重定向
1 | 重定向输出流到文件或另一个流。 |
< 输入重定向
1 | 输入重定向 |
重定向标准输出和标准错误流到 log.txt 文件 ?
1 | 在脚本文件中添加 exec >log.txt 2>&1 命令的作用是将脚本的标准输出(stdout,文件描述符为1,这里省略了完整应该是 exec 1>log.txt 2>&1)和标准错误输出(stderr,文件描述符为2)都重定向到同一个文件(在这个例子中是log.txt $表示绑定 &1表示和1绑定)中。这意味着,无论脚本在运行时输出到控制台的信息还是错误信息,都会被写入到log.txt文件中,而不是显示在终端或控制台上。 |
1 | Linux的IO输入输出有三类 |
1 | ls 1>/dev/null 2>/dev/null |
如果给定字符串 variable=”User:123:321:/home/dir”,如何只用 echo 命令获取 home_dir ?
1 | variable="User:123:321:/home/dir" |
1 | 其中 # 符号用于从变量值中删除最短匹配指定模式的部分。具体来说,${variable#pattern} 会从变量 variable 的值中删除最短匹配 pattern 的部分,并返回剩余的部分 |
1 | # 表示从变量值的开头开始删除。 |
如何从上面的字符串中获取 “User” ?
1 | echo ${variable%:*:*:*} |
1 | 在 Bash 脚本中,${variable%:*:*:*} 和 ${variable%%:*} 使用了参数扩展(Parameter Expansion)功能的不同模式,它们都是用于从变量值的末尾开始删除内容,但删除的方式略有不同。 |
如何列出第二个字母为 a 或 b 的文件?
1 | ls -d ?[ab]* |
tr命令
1 | 以下是tr命令的一些常用选项: |
1 | 将小写字母转换为大写字母: |
tr 如何从字符串中删除所有空格?
1 | [root@bigdata02 myshells]# c=`echo $a|tr -d "j"` |
[ $a == $b ] 和 [ $a -eq $b ] 有什么区别
1 | [ $a == $b ] - 可以用于字符串比较 |
=和==
1 | = 和 == 之间有什么区别 |
[[ $string == abc* ]] 和 [[ $string == “abc*” ]] 有什么区别
1 | [[ $string == abc* ]] - 将检查字符串是否以 abc 字母开头 |
硬链接和软链接
1 | 软连接: |
1 | 软连接为目录时: |
1 | 删除软链接 rm 名字 |
1 | 硬链接: |
1 | ln [目标文件] [链接名] |

date
获取系统当前时间
1 | 1.date命令默认获取系统当前时间 |
格式化
1 | 2.date命令支持对时间进行格式化 |
时间戳
1 | 3.时间戳 |
获取指定时间的时间戳
1 | date命令 提供的有--date这个参数,可以指定时间 |
1 | $ date --date="2024-10-28" +%s |
/etc/profile和/etc/profile.d
1 | /etc/profile 文件 登录或者切换用户都会读这个文件 全局的 |
1 | [root@bigdata02 profile.d]# ll |
命令
read读取控制台输入
1 | read(选项)(参数) |
1 | >>vi read.sh |
使用管道或重定向
1 | 你还可以通过管道(|)或输入重定向(<)来传递数据给 Shell 脚本,这允许你将其他命令的输出作为输入传递给脚本。 |
whoami users
1 | whoami |
test
1 | test 命令可以用来测试文件。 |
1 | [root@bigdata02 myshells]# test -f while.sh |
grep
1 | ll|grep hudi |
netstat
1 | 查看监听端口 |
ls -al
1 | .开头的路径和文件 ls不会显示 |
useradd
1 | adduser ty |
用户组 groupadd
1 | groupadd mysql 用户组添加 |
chown
1 | chown 命令,可以认为是 "change owner" 的缩写,主要用于修改文件(或目录)的所有者,除此之外,这个命令也可以修改文件(或目录)的所属组。 |
1 | 修改文件的拥有者 |
chgrp
1 | 修改文件的所属组 |
权限 chmod
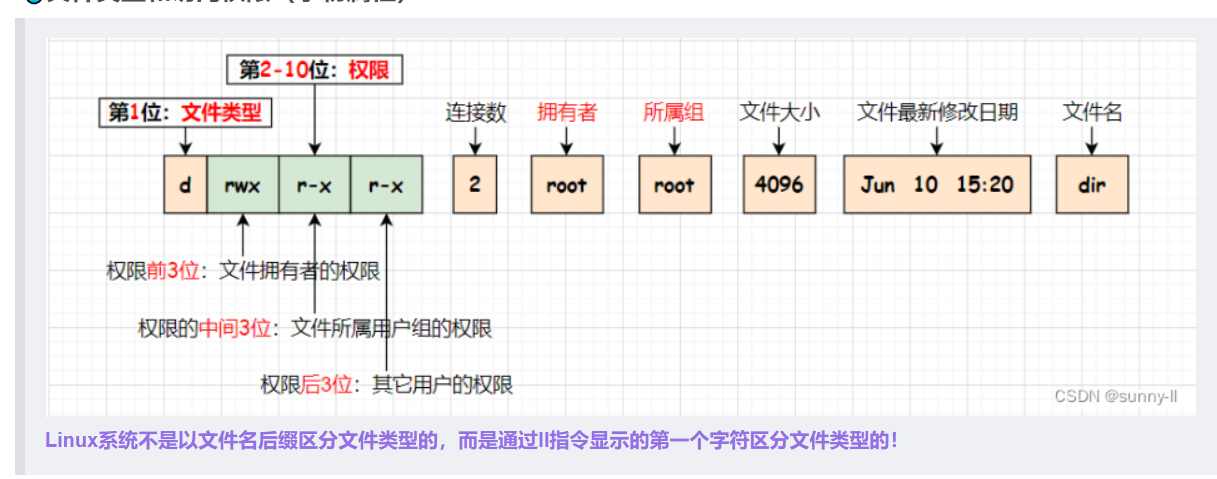
1 | 超级用户的命令提示符是“#”,普通用户的命令提示符是“$” |
1 | drwxr-xr-x. 4 root root 38 Feb 26 13:18 xdg |
1 | chmod |
ps -ef|grep runJar
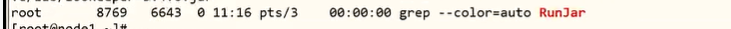
1 | runjar是hive的服务 |
jstat -gcutil PID 1000
1 | 通过jstat -gcutil PID 1000来看看这个进程GC的信息,每一秒钟刷新一次,如果GC次数增长过快,说明内存不够用 |
ip addr|ifconfig
touch cat more
1 | touch 创建文件 |
tail head
1 | tail -f 文件 动态显示 |
1 | 如何获取文本文件的第 10 行 ? |
1 | 获取文件的最后/第一行? |
echo
1 | echo:将内容输出到设备,类似java里面的system.out.println() |
history
1 | history保留了最近执行的命令记录,默认可以保留1000。 |
df
1 | df -h 查看容量空间 还有磁盘 |
vi
1 | 1.查找字符串 对文件中字符串的快速查找 |
1 | 命令行模式下输入 |
1 | 有时候不想费劲看多少行或复制大量行时,可以使用标签来替代 |
1 | 5.快速删除 |
wc
1 | wc -w 统计单词数 默认空格为分隔符 |
uniq
1 | uniq:检查重复的行列 |
1 | [root@bigdata02 myshells]# vi /data/uniqdata.txt |
ps
1 | 显示进程信息 |
1 | 显示出这个信息其实说明没有找到java进程信息,下面返回的这一行表示是grep进程本身,这样容易给我们造成错觉,想把它去掉,怎么去掉呢? |
netstat
1 | netstat也是显示进程相关信息的,只不过可以比ps命令额外显示端口相关的信息 |
1 | 这里会显示很多的进程和端口信息,netstat也需要和grep命令结合使用 |
jps
1 | jps:类似ps命令,不同的是ps是用来显示所有进程信息的,而jps只显示Java进程 |
top
1 | 主要作用在于动态显示系统消耗资源最多的进程信息,包含进程ID、内存占用、CPU占用等 |
free
1 | 查看内存使用情况 |
kill
1 | 可以使用前面学习的ps命令,找到程序对应的PID,然后使用kill命令杀掉这个进程,进程被杀掉了,对应的程序也就停止了 |
uname
1 | 查看系统架构 |
locate
1 | locate命令其实是“find -name”的另一种写法,但是要比后者快得多,原因在于它不搜索具体目录,而是搜索一个数据库(/var/lib/locatedb),这个数据库中含有本地所有文件信息。Linux系统自动创建这个数据库,并且每天自动更新一次,所以使用locate命令查不到最新变动过的文件。为了避免这种情况,可以在使用locate之前,先使用updatedb命令,手动更新数据库。 |
1 | locate命令的使用实例: |
压缩 解压
1 | 常见用法:压缩和解压 |
curl
1 | root@VM-16-2-tencentos:/workspace/production_system# curl -X POST http://10.226.1.155/graphql \ |
which | whereis | find | locate
which
1 | which命令的作用是,在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。也就是说,使用which命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。 |
whereis
1 | whereis命令用于搜索程序的二进制文件,源代码文件或帮助文档。例如: |
find
以名称为条件
1 | find / -name guava* |
以权限为条件
1 | 有时候需要查找特定权限的文件,可以使用-perm参数,例如查找当前目录下权限为777的文件: |
以文件类型为条件
1 | 涉及参数-type,例如要查找当前目录下的符号链接文件: |
以文件大小为条件
1 | 涉及参数-size,例如: |
以归属为条件
1 | 涉及参数-user,-nouser,-group,-nogroup等,例如: |
以时间为条件
1 | 涉及参数-mtime,-atime,-ctime,-newer,-anewer,-cnewer,-amin,-cmin等,例如: |
shell工具 重点
cut
1 | cut 的工作就是“剪”,具体的说就是在文件中负责剪切数据用的。cut 命令从文件的每行剪切字节、字符和字段并将这些字节、字符和字段输出。。 |
1 | cut [选项参数] filename |
1 | >>vi cutdata.txt |
1 | [root@bigdata02 myshells]# cut -d " " -f 1 ./data/cutdata.txt |
cut结合| grep
1 | >cat ./data/cutdata.txt | grep wangming |
1 | 切path |
1 | 切出ip 这个也是看的我有点懵逼 首先切割符必须为单个字符,后面空格不规范时我就有点蒙蔽了 |
1 | [root@bigdata01 sbin]# ifconfig |
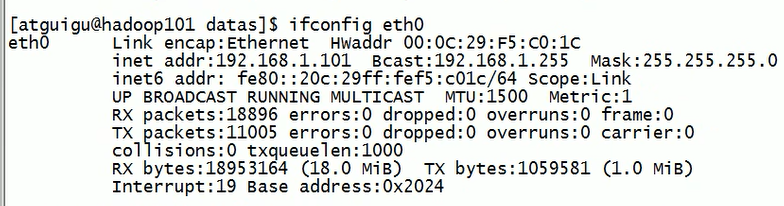

1 | 它这里使用的空格分割,避免了麻烦事 |
如何列出以 ab 或 xy 开头的用户名?
1 | grep "^ab|^xy" /etc/passwd|cut -d: -f1 |
sed
1 | sed 是一种流编辑器它一次处理一行内容处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间接着用 sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。文件内容并没有改变,除接着处理下一行,这样不断重复,直到文件末尾。除非你使用重定向存储输出。” |
1 | sed [选项参数] 'command' filename |
1 | -e |
1 | a 新增,a的后而可以接字串,在下一行出现($表示最后一行) |
增加
1 | 原文件没改变 |
1 | [root@bigdata02 myshells]# vi /data/seddata.txt |
1 | [root@localhost ~]# sed '1a\haha' hello.txt 此操作会将数据添加到第一行下面(也就是第二行的位置) |
删除
1 | >>sed '/wo/d' data/seddata.txt |
1 | [root@localhost ~]# sed '7d' hello.txt |
替换
1 | sed [address]s/pattern/replacement/flags |
1 | >>sed 's/wo/ni/g' data/seddata.txt |
1 | sed 's/l/a/1' hello.txt 一行中匹配的第一次替换 |
1 | 我们现在的替换操作都是会匹配文件中的所有行,如果我们只想替换指定行中的内容怎么办呢?只需要增加address 参数即可。 |
-i 修改源文件
1 | 注意了,咱们前面所讲的sed命令的所有操作,在执行之后都不会修改源文件中的内容,这样只能作为测试,如果需要修改源文件的话,其实也很简单,只需要增加一个 -i 参数即可 |
多语句
1 | >>sed -e "2d" -e "s/wo/ni/g" data/seddata.txt |
awk
1 | 一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。 |
1 | awk「选项参数] ‘patternl {actionl} pattern2 {action2}...’ filename. |
1 | -F 指定输入文件折分隔符(分隔符与F有无空格都可以) |
1 | 取以root开头那一行,用:分隔 取第七列 |
1 | [root@bigdata02 myshells]# cat /etc/passwd |
1 | 2)搜索 passwd 文件以 root 关键字开头的所有行,并输出该行的第1列和第7列,中间以,号分割。 |
1 | 还有一个特殊的 $0 它代表整个文本行的内容 |
1 | 如果我们只想对某一列数据进行匹配呢? |
获取一个文件每一行的第三个元素 ?
1 | awk的基本格式:awk [option] programe file |
1 | https://tianyong.fun/linux%E7%9B%B8%E5%85%B3%E5%91%BD%E4%BB%A4%E5%92%8C%E5%BC%82%E5%B8%B8.html |
假如文件中某行第一个元素是 FIND,如何获取第二个元素
1 | awk'{ if ($1 == "FIND") print $2}' |
如何使用 awk 列出 UID 小于 100 的用户 ?
1 | awk -F: '$3<100' < /etc/passwd |
BEGIN END
1 | 注意:BEGIN 在所有数据读取行之前执行;END在所有数据执行之后执行, |
1 | [root@bigdata02 myshells]# awk -F : '{print $1","$7}' data/passwd | sed -e '1i user,shell' -e '$a tianyong,/bin/zhenbang' |
1 | 3)只显示/etc/passwd 的第一列和第七列,以逗号分割,且在所有行前面添加列名user, |
-v
1 | 将passwd 文件中的用户id增加数值1并输出 |
1 | 这里换成{print $3+$i} {print $3+1} {print "$3+1"} {print $[$3+1]} {print "$[$3+1]"}都不行 |
awk的内置变量
1 | FILENAME 文件名。 |
1 | 统计 passwd 文件名,每行的行号,每行的列数 |
1 | 切割ip |
1 | 查询 sed.txt 中空行所在的行号, |
sort
1 | sort命令是在Limux里非常有用,它将文件进行排序,并将排序结果标准输出。 |
1 | sort (选项) (参数) |
1 | >>vi sortdata.txt |
文件系统
1 | window NTFS |
shell脚本

1 | Shell是一个命令行解释器,它接收应用程序/用户命令,然后调用操作系统内核。 |
shell解释器
1 | 每个脚本开始的 #!/bin/sh 或 #!/bin/bash |
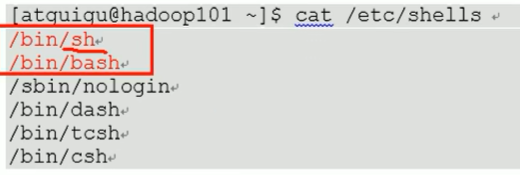
1 | 查看shell支持哪些解释器 |

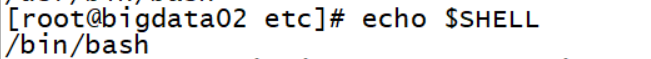
shell脚本入门
hello world
1 | touch ~/myshells/helloworld.sh |

1 | -rw-r--r--. 1 root root 31 Oct 15 10:30 helloworld.sh |

1 | >>chmod 777 helloworld.sh |

1 | 注意:第一种执行方法,本质是bash解析器帮你执行脚本,所以脚本本身不需要执行权限。第二种执行方法,本质是脚本需要自己执行,所以需要执行权限 |
多命令处理
1 | 在~/myshells/data日录下创建一个data.txt,在data.txt文件中增加“hello world” |
1 | #!/bin/bash |
shell中的变量
系统变量
1 | $PWD $SHELL $HOME $USER |
自定义变量
定义变量
1 | 变量=值 等号两边不能有空格 |
撤销变量
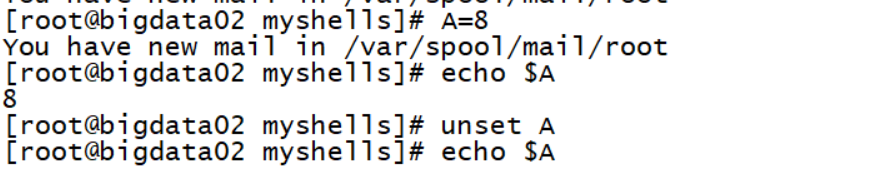
1 | >>unset A |
声明静态变量
1 | readonly B=5 不能撤销 |

变量名定义规则
1 | (1)变量名称可以由字母、数字和下划线组成,但是不能以数字开头,环境变量名建议大写。 |

1 | >>echo 1+1 |

1 | >>echo I love her |

局部变量提升为全局变量
1 | 可把变量提升为全局环境变量,可供其他She11程序使用 |
1 | >>E="I love her" |
特殊变量
$n
1 | 1-9个参数用$n |
1 | vi parameters.sh |

$#
1 | S# (功能描述:获取所有输入参数个数,常用于循环) |
1 | >>vi parameters.sh |
$*和$@
1 | $* (功能描述:这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体) |
1 | >>vi parameters.sh |
$?
1 | $? (功能描述:最后一次执行的命令的返回状态。如果这个变量的值为0,证明上一个命令正确执行;如果这个变量的值为非0(具体是哪个数,由命令自己来决定),则证明上一个命令执行不正确了。)“ |
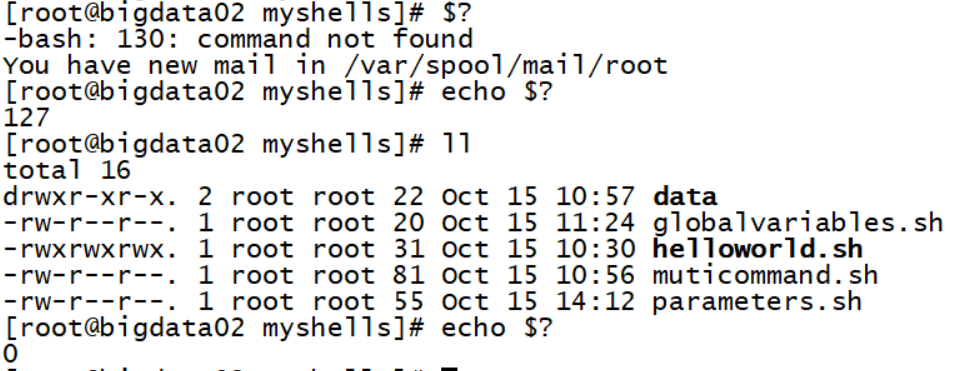
$!
1 | 最近的后台命令PID |
$??
1 | 最近的前台退出状态。 |
$$
1 | 如何打印当前shell的PID? |
嵌套脚本
1 | #!/bin/bash |
1 | #!/bin/bash |
1 | #!/bin/bash |
变量
1 | 在 shell 脚本中,变量默认是全局作用域的 |
set -e
1 | set -e是 Shell 的一个错误处理选项,意思是 "exit on error"(遇到错误立即退出)。 |
函数
1 | show_help() { |
1 | parse_args() { |
1 | shift是 shell 内置命令,用来移动位置参数($1, $2, $3...)。 |
1 | show_config() { |
1 | main() { |
脚本中使用命令
1 | $(whoami) |
运算符
1 | (1)“$((运算式))”或“$[运算式]” |
加
1 | >>expr 2+3 |
乘
1 | >>expr `expr 2 + 3` \* 5 |
1 | >>echo $[(2+3)*5] |
调试 bash 脚本
使用 -x 选项
1 | 通过在运行脚本时使用 -x 选项,Bash 会在执行每一行命令之前打印该命令。这有助于查看脚本的执行流程和变量的值变化。 |
设置 set 命令
1 | 在脚本内部,可以使用 set 命令来开启或关闭调试模式。set -x 会打开调试模式,set +x 会关闭调试模式。 |
逐步调试 -v
1 | Bash 的 -v 选项可以打印出脚本中的每一行命令,就像它们从脚本中读取出来一样,而不是执行后的结果。这有助于了解脚本的流程。 |
函数 了解
1 | shell开发工程师需要重点掌握 |
系统函数
basename基本语法
1 | basename [string/pathname][suffix] |
1 | [root@bigdata02 myshells]# basename /root/myshells/read.sh |
dirname基本语法
1 | dirname 文件绝对路径 |
1 | [root@bigdata02 myshells]# dirname /root/myshells/for.sh |
自定义函数
1 | [function] funname[()] |
1 | #!/bin/bash |
1 | #!/bin/bash |
1 | (1)必须在调用函数地方之前, |
1 | >>vi function.sh |
1 | [root@bigdata02 myshells]# sh function.sh |
企业真实面试题
1 | 使用 Limux 命令查询 fle1 中空行所在的行号 |
1 | 问题 2:有文件 chengji.txt 内容如下: |
1 | awk 'temp=$8;getline;print temp","$8' |
1 | 问题1:Shel 脚本里如何检查一个文件是否存在?如果不存在该如何处理?。 |
1 | 问题:对文件内数据排序,最后输出总和 |
grep的高级使用
1 | 要在某个路径下递归查找所有包含特定字符串的文件,可以使用 grep 命令结合一些选项进行操作。grep 是一种强大的文本搜索工具,可以在文件中搜索匹配指定模式的字符串。当与递归搜索选项结合使用时,grep 能够在指定目录及其所有子目录中搜索文件内容。 |
1 | 问题1:请用shell 脚本写出查找当前文件夹(ome)下所有的文本文件内容中包含有字符”shen”的文件名称 |
1 | 常用于查找文件里符合条件的字符串 |
1 | [root@localhost ~]# ps -ef | grep java |
Shell 添加一个新组为class1,添加属于这个组的30个用户,用户名的形式为stdxx,其中xx从01 到30 ?
1 | 要实现这个需求,你可以编写一个 Shell 脚本来首先创建一个名为 class1 的新组,然后循环添加用户名为 std01 到 std30 的用户,并将这些用户分配到 class1 组。下面是一个简单的脚本示例,演示了如何执行这些操作: |
获取行首行位几行
1 | head -n |
‘ 和 “ 引号之间有什么区别?
1 | Bash 使用过程中,经常会用双引号或单引号将字符串括起来,也可以不使用引号来定义字符串变量。 |
单引号
1 | 单引号是全引用,被单引号括起的内容不管是常量还是变量都不会发生替换。 |
双引号
1 | 双引号引用的内容,所见非所得。如果内容中有命令、变量等,会先把变量、命令解析出结果,然后在输出最终内容。双引号是部分引用,被双引号括起的内容常量还是常量,变量则会发生替换,替换成变量内容。 |
无引号
1 | 不使用引号定义字符串时,字符串不能包含空白字符(如 Space 或 Tab),需要加引号。一般连续的字符串、数字、路径等可以不加引号。如果内容有命令、变量等,会先把变量、命令解析出结果,然后再输出最终内容。 |
建议
1 | 字符串常量使用单引号括起来,如果字符串含有变量、命令等使用双引号括起来,不建议不加引号。 |









