数据库系统-常用用法积累
数据库系统-常用用法积累
智汇君数据库系统-常用用法积累
Delete
注意
1 | 删除重复邮件,保留最小的id email 来自leecode |
1 | # Write your MySQL query statement below |
1 | 如果不要貌似多余的select t.id from ( 会报错 |
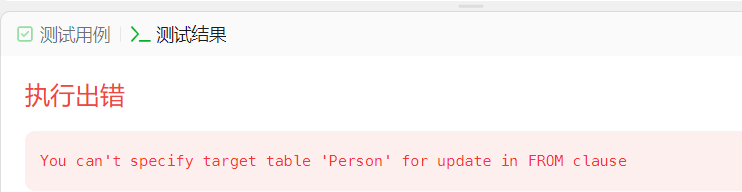
1 | delete from Person where id not in ( |
1 | DELETE p1 FROM Person p1, |
1 | p1是Person表的别名,这个DELETE语句会删除Person表中所有满足JOIN条件和WHERE条件的行 |
日期
DATEDIFF()
1 | DATEDIFF() 函数返回两个日期之间相差的时间。周、月数、年数可以除以7、30、365然后向上CEIL或者向下FLOOR取整粗略计算。 |
TIMESTAMPDIFF() | NOW()
1 | timestampdiff(year,参数1,参数2) |
1 | select w1.Id |
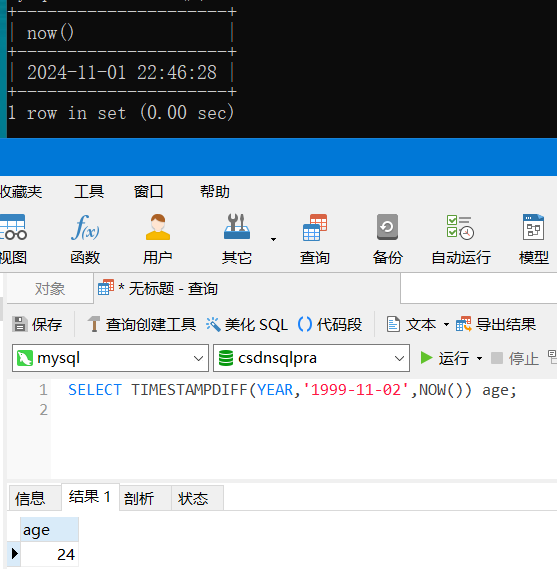
1 | SELECT TIMESTAMPDIFF(YEAR,'1999-11-02',NOW()) age; |
DATE_FORMAT()
1 | %b 缩写月名 |
1 | --2018-12-18 |
DATE_ADD()
1 | DATE_ADD() :从日期增加指定的时间间隔,返回的是一个字符串 |
1 | select IFNULL(round(count(distinct(Result.player_id)) / count(distinct(Activity.player_id)), 2), 0) as fraction |
DATE_SUB()
1 | 用于从日期减去指定的时间间隔。它与 DATE_ADD() 函数具有相似的用法。 |
CURDATE(),NOW()
1 | mysql> select curdate(); |
MONTH(),WEEK(),YEAR(),DAYOFMONTH()
1 | MONTH提取日期中的月 |
DAYOFWEEK、DAYOFMONTH、DAYNAME
1 | DAYOFWEEK函数接受1个参数,即DATE或DATETIME值。 它返回一个整数,范围从1到7,表示星期日到星期六。如果日期为NULL,零(0000-00-00)或无效,则DAYOFWEEK函数返回NULL。 |
1 | DAYOFMONTH提取日期中的天 |
lag()、lead()
1 | lag()和lead()这两个函数可以查询我们得到的结果集上下偏移相应行数的相应的结果。 |
1 | with people as |
1 | 当比如第一行取lag前一行,为null |
数学
roud()
1 | SELECT T.request_at AS `Day`, |
mod(M,N)
1 | 取余函数 |
ABS(p1.x_value - p2.x_value)
1 | 取绝对值 |
sqrt()开平方
1 | sqrt(A)对A开平方根 |
FLOOR、CEIL
1 | FLOOR()函数返回小于或等于给定数字的最大整数值 |
1 | CEIL() 函数返回大于或等于给定数字的最小整数值。这个函数等同于 CEILING() 函数 |
limit()
1 | limit 2 ==>从0索引开始读取2个 |
一个参数
1 | limit 10 |
两个参数
1 | limit 0,2 第一个参数表示从第几行开始取,第二个表示取几行 |
分页offset
1 | 例如,把结果集分页,每页3条记录。要获取第1页的记录,可以使用LIMIT 3 OFFSET 0: |
IF
if()
1 | IF(T.STATUS = 'completed',0,1) |
IFNULL()、NULLIF()、ISNULL()
1 | IFNULL()函数的使用 |
1 | NULLIF()函数的使用 |
1 | ISNULL()函数的使用 |
=、<=>、NULL、is null、is not null
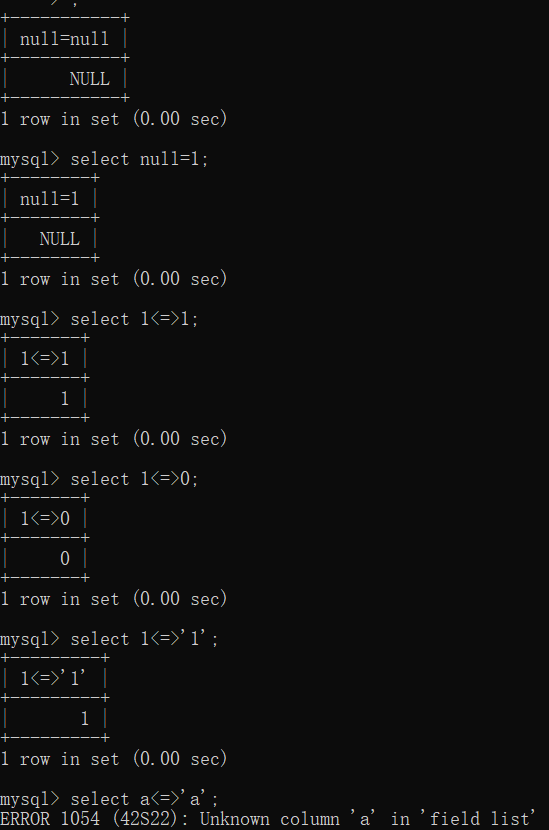
1 | MySQL提供了IS NULL和IS NOT NULL这两个操作符,它们专门用于检查字段是否为NULL。当我们使用IS NULL时,如果字段的值为NULL,查询将返回TRUE;如果字段的值不是NULL(包括字段中有值和字段为空),查询将返回FALSE。 同样地,IS NOT NULL用于检查字段值是否不是NULL。 |
1 | 普通的=,不能用于null的比较,两个式子中有一个或者两个null结果为null |
1 | 1<=>0 ‘2’<=>2 2<=>2 ‘b’<=>‘b’ (1+3)<=>(2+2) NULL<=>NULL NULL<=>‘1234’ NULL<=>123 ‘456’<=>NULL |
1 | mysql中两个字符串比较按照字符串规则来,字符串和数字比较,字符串转换成数字比较 |
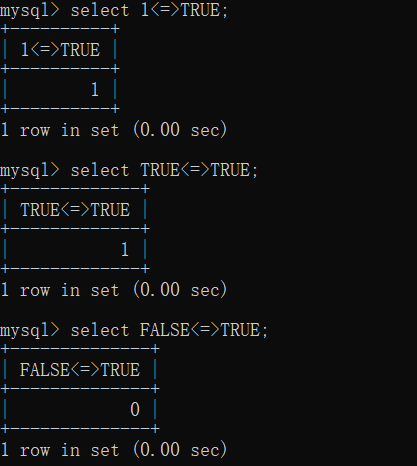
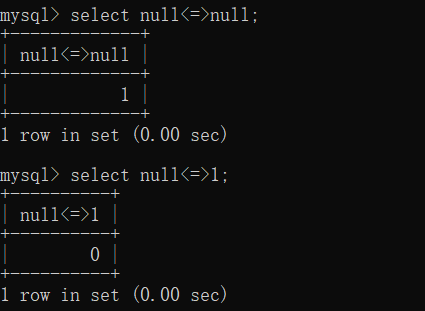
1 | 安全等于可以用于比较null,同null为1,一个则为0。其它情况和=类似 |
1 | 输入: |
WITH语句
1 | WITH BaseSalary AS ( |
1 | WITH cte_name (column_name1, column_name2, ...) AS ( |
1 | 在SQL查询中,经常会遇到需要重复使用的子查询。为了简化查询语句并提高可读性,SQL引入了WITH AS语法。通过使用WITH AS,我们可以创建临时表或视图,将子查询的结果保存起来,并在主查询中使用。本文将通过示例介绍SQL中WITH AS的特点,展示其在查询中的优势。 |
1 | 1. 简化复杂查询 |
1 | 2. 提高查询性能:使用WITH AS可以避免在主查询中重复执行相同的子查询,从而提高查询性能。临时表的结果会被缓存,主查询只需要引用临时表即可,避免了重复计算子查询的开销。 |
1 | with people as |
group by
1 | SELECT DATE_FORMAT(trans_date, '%Y-%m') AS month, |
1 | select e.student_id,student_name,count(*) attended_exams |
having
1 | --leecode 3328 |
变量
1 | Queue 表 |
1 | SELECT a.person_name |
窗口函数
1 | mysql8.0时开始支持 |
1 | 通常将常用的窗口函数分为两大类:聚合窗口函数与专用窗口函数。 |
| SUM | 求和 |
|---|---|
| AVG | 求平均值 |
| COUNT | 求数量 |
| MAX | 求最大值 |
| MIN | 求最小值 |
函数名 分类 说明
RANK 排序函数 类似于排名,并列的结果序号可以重复,序号不连续
DENSE_RANK 排序函数 类似于排名,并列的结果序号可以重复,序号连续
ROW_NUMBER 排序函数 对该分组下的所有结果作一个排序,基于该分组给一个行数
1 | [你要的操作] OVER ( PARTITION BY <用于分组的列名> |
1 | 窗口函数([参数]) OVER ( |
rows between and
1 | <窗口滑动的数据范围> 用来限定[ 你要的操作] 所运用的数据的范围,具体有如下这些: |
1 | 举例理解一下: |
range between and
1 | range表示的是 具体的值,比这个值小n的行,比这个值大n的行 |
1 | 前面的current row、following、preceding、unbounded也可以用。等同于前面的row between and |
dense_rank() over
1 | SELECT SId,totalscore,DENSE_RANK()over(ORDER BY totalscore DESC) r |
avg(x) over()
1 | SELECT |
CASE
1 | case语句格式一 |
1 | case语句格式二 |
1 | case when ... then x else x end |
1 | case when sc.cid='01' then sc.score end |
||
1 | sql语句中“||”符号表示,连接符。比如'111'||'222'其结果就是'111222'。 |
行转列、列转行
1 | 行转列一般使用 IF 或 CASE WHEN 语句 + GROUP BY + 聚合函数。而列转行一般使用 UNION + 多个查询 的方法 |

表连接
全外连接
1 | mysql不支持全外连接 |
笛卡尔积、CROSS JOIN
1 | sql笛卡尔积 |
1 | SELECT |
集合运算
union和union all
1 | union会去重 |
where
where (player_id, event_date) in select a,b
1 | select player_id, device_id |
order by和limit一起使用注意事项
1 | 如果 order by 的列有相同的值时,MySQL 会随机选取这些行 |
1 | 当order by的列有重复值时, |
聚合函数
count(**)\count(*0)\count(1)
1 | 按照效率排序的话:count(字段)< count(主键id)< count(1)= count(*),所以尽量使用count(*). |
递归 recursive
1 | 题目1613 1270 3482 |
1 | 有两种递归字段n的声明写法,第一种是在with… as 中声明需要递归的字段,第二种是在sql语句中第一段的初始值内声明变量。 |
1 | 1.生成数字序列 |
1 | 2.树状或者层级结构 |

类型转换
cast
1 | CAST(expression AS TYPE) 函数可以将任何类型的值转换为具有指定类型的值,利用该函数可以直接在数据库层处理部分因数据类型引起的问题 |
1 | 支持的TYPE类型 描述 |
convert
1 | CONVERT(value, type) |
字符串
字符串拼接
1 | 1.concat('xxx',num) |
1 | 避免用 + 运算符 |
substring_index substring
substring_index
1 | 按关键字进行读取 |
1 | SUBSTRING_INDEX是MySQL中的一个非常实用的字符串截取函数。 |
1 | -- 获取第一个逗号前的字符串 |
1 | --当不满足条件时,返回整个字符串 |
substring()
1 | 不是下标为0开始 |
1 | substring(str, pos),即:substring(被截取字符串, 从第几位开始截取) |
1 | -- 当超出字符范围时,返回空字符'' |
instr
1 | INSTR函数用于返回子字符串在字符串中第一次出现的位置。如果子字符串不存在,则返回0 |
1 | 使用BINARY运算符可以使搜索区分大小写 |
1 | INSTR函数也可以用于模糊查询,类似于LIKE运算符 |
left right
1 | left(str,n) --从左起截n个 |
length
1 | 字符串字符数 |
TRIM
1 | TRIM() 函数用于从字符串的开头和结尾删除指定字符,默认情况下删除空格 |
UPPER LOWER
1 | UPPER(expression):将字符串表达式转换为大写。 |
GROUP_CONCAT() CONCAT() CONCAT_WS()
contcat()
1 | 无连接符 |
1 | 指定连接符 |
concat_ws()
1 | CONCAT_WS()是 CONCAT With Separator 的缩写 |
1 | SELECT CONCAT_WS(' / ', firstname, phone, subject, qualification) AS Detail FROM kalacloud_student; |
group_concat()
1 | 可以指定自定义的分隔符,不指定的情况下,默认是 ',' |
例
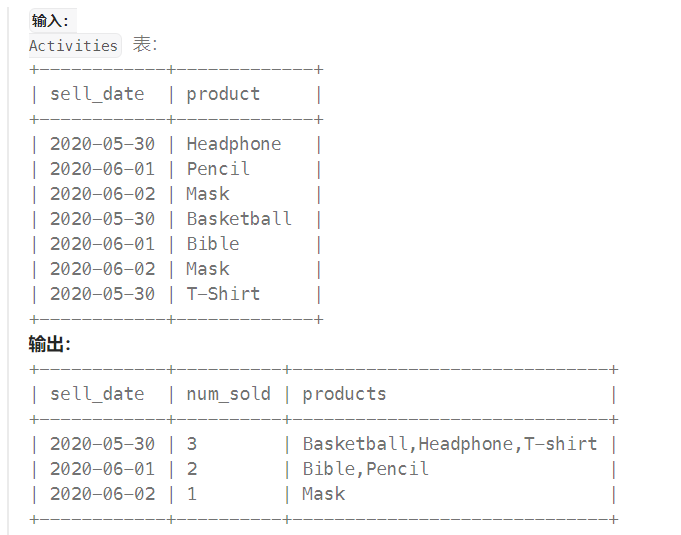
1 | SELECT sell_date, |
1 | select |
正则表达式 REGEXP regexp_like
1 | dna_sequence REGEXP 'xxx' |
1 | REGEXP_LIKE(string, pattern, match_type) |
1 | rlike和regexp一样的效果 |
REPLACE
1 | replace(str,'a','') |









