大数据开发工程师-第十五周 Spark 3.x版本扩展内容
大数据开发工程师-第十五周 Spark 3.x版本扩展内容
智汇君大数据开发工程师-第十五周 Spark 3.x版本扩展内容
快速上手使用Spark3
Spark 3.0.0版本介绍
1 | Spark3.0.0版本是Spark 3.x系列的第一个正式版本,他于2020-6-10日正式发布。 |
Spark 3.x的使用
1 | Spark3.x的核心代码和Spark 2.x没有什么区别,目前我们在常规使用中暂时还没有发现什么不兼容的情况。 |
基于Spark 3.x版本开发代码
1 | 首先基于Spark 3.x版本开发一套WordCount的代码 |
1 | 代码直接参考之前的写法即可。 |
在已有的大数据集群中集成Spark 3.x环境
1 | 在Spark ON YARN架构下,之前默认是使用的Spark2.x环境,现在想要在已有的大数据集群中集成Spark 3.x环境,操作是非常简单的。 |
1 | 1.将spark-3.2.1-bin-hadoop3.2.tgz压缩包上传到bigdata04的/data/soft目录中。 |
向YARN中同时提交Spark 2.x和Spark 3.x的代码
编译打包
1 | 首先向YARN集群中提交Spark 3.x的代码 |
1 | package com.imooc.scala.rdd |
1 | 增加编译打包配置。 |
1 | <build> |
提交任务
1 | 2.提交任务。 |
1 | 注意:在这里需要指定spark-submit的全路径,要不然容易冲突,因为这个客户端节点上有两个版本的spark,他们都有spark-submit脚本。 |
1 | 修改spark 3.2.1中的spark-submit脚本名称。 |
1 | 执行任务脚本: |
1 | 通过查看Caused by后面的报错信息可以大致看出来是和scala有关的,如果不能指定定位到具体问题,可以尝试把这个核心错误信息(scala.runtime.java8.JFunction2$mcIII$sp)拿到网上查一下 |
1 | 通过查询公开资料大致可以知道是因为编译环境的scala版本和执行环境的scala版本不一样导致的。 |
1 | 这两个zip压缩包是Spark客户端在提交任务的时候,从本地的spark安装包中得到的。 |
1 | 把下载下来的这个zip包传到windows中,解压查看一下 |
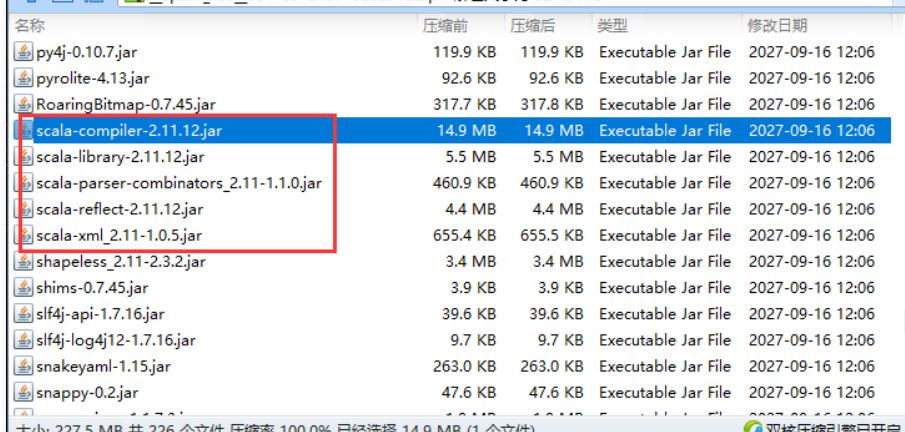
1 | 此时发现这里面的scala依赖确实是2.11版本的。 |
1 | 此时发现这里面scala的jar包都是2.12版本的,和我们代码编译时使用的大版本是一致的,只要都是2.12版本就行,后面的第3位小版本号不用太过于关注,一般都是兼容的。 |
1 | 此时发现这里面的scala版本就是2.11.12,和任务运行期间生成的那个zip包中的依赖版本是一致的。 |
1 | [root@bigdata04 bin]# vi spark-submit-3 |
1 | 重新提交任务。 |
historyserver
1 | 到这其实大家还有一个疑问,现在是有2个版本的spark,那对应的historyserver服务是不是也需要启动2个? |
1 | 然后修改spark-env.sh |
1 | 启动spark的historyserver服务,在bigdata04上执行。 |
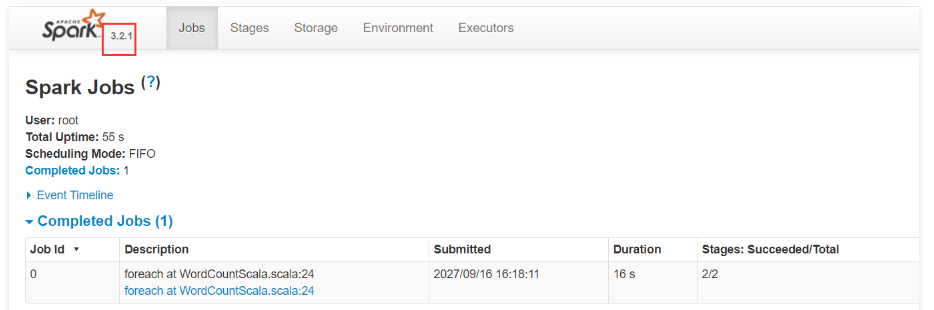
1 | 接下来提交一个spark 2.x版本的代码。 |
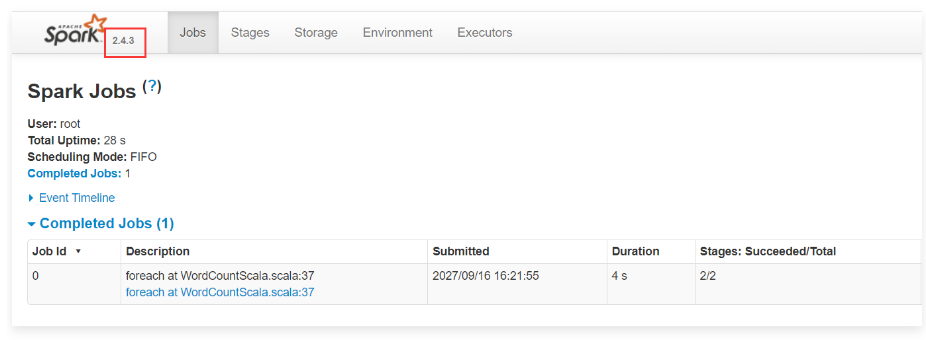
1 | 到这里我们可以支持在同一个YARN集群中同时执行spark 2.x和spark 3.x版本的代码,并且对应的spark 任务界面也都是正常的。 |
Spark 3.x版本中新特性的原理及应用
Spark 1.x~3.x的演变历史
1 | 在Spark 1.x中,主要是通过Rule这个执行框架,把一批规则应用在一个执行计划上进而得到一个新的执行计划。 |
1 | 因此,spark 3.0在Cost基础之上增加了Runtime,Runtime可以收集任务在运行期间的统计信息,实现动态优化任务的执行计划。 |
Spark 3.x新特性
1 | 下面来看一下Spark 3.x版本中具有代表的新特性 |

1 | 总结下来大致包括下面这几个: |
自适应查询执行
1 | 自适应查询执行:可以简称为AQE。它是对Spark执行计划的优化,它可以基于任务运行时统计的数据指标动态修改Spark 的执行计划。 |

1 | 每个Stage内部都会有一系列的执行逻辑。 |
自适应调整Shuffle分区数量
1 | Spark在处理海量数据的时候,其中的Shuffle过程是比较消耗资源的,也比较影响性能,因为它需要在网络中传输数据。 |
1 | 那么这个自适应调整Shuffle分区数量的底层策略是怎么实现的呢? |
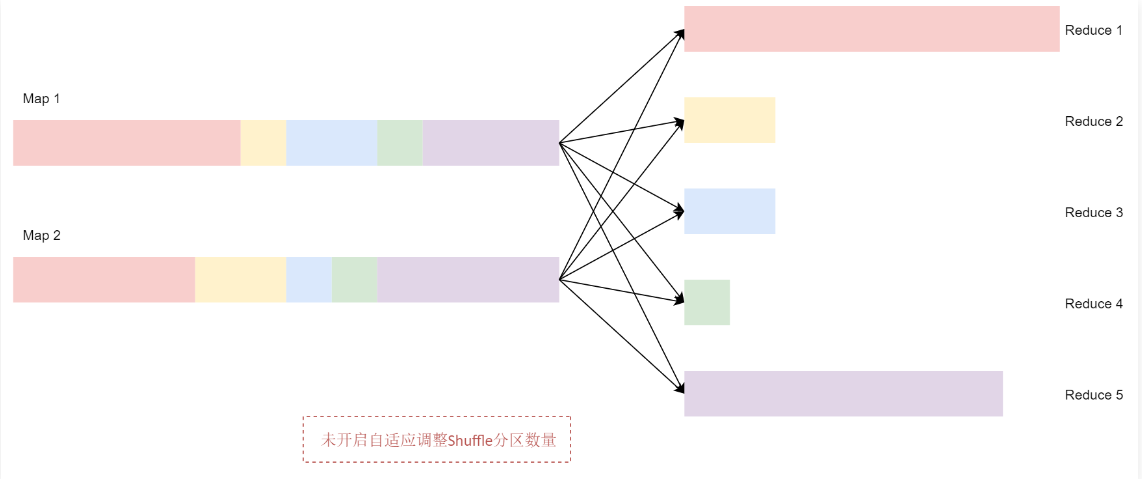
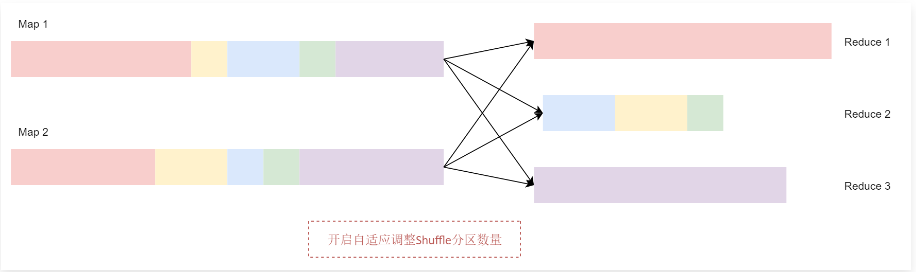
1 | 开启自适应调整Shuffle分区数量之后,Spark 会将这3个数据量比较小的分区合并为1个分区,让1个reduce任务处理,这个时候最终的聚合操作只需要启动3个reduce任务就可以了。 |
1 | 关于自适应调整Shuffle分区数量这个机制的核心参数主要包括下面这几个: |
1 | spark.sql.adaptive.enabled:这个参数是控制整个自适应查询执行机制是否开启的,也就是控制AQE机制的。默认值是true,表示默认是开启的。 |
1 | 这些参数在官网文档中也是可以找到的,我们来看一下: |
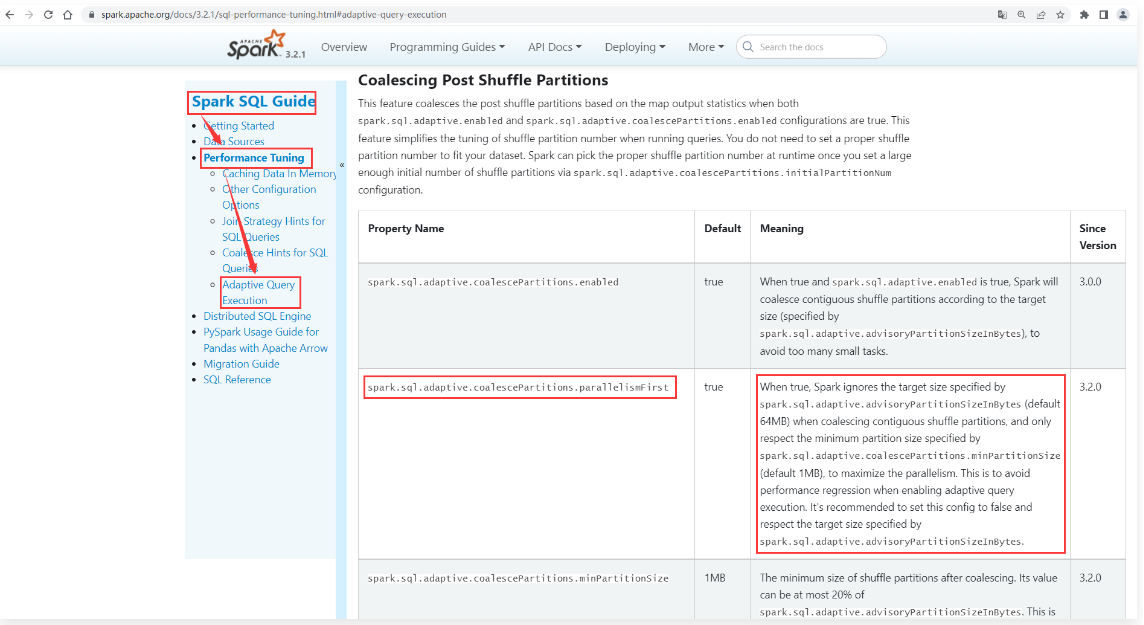
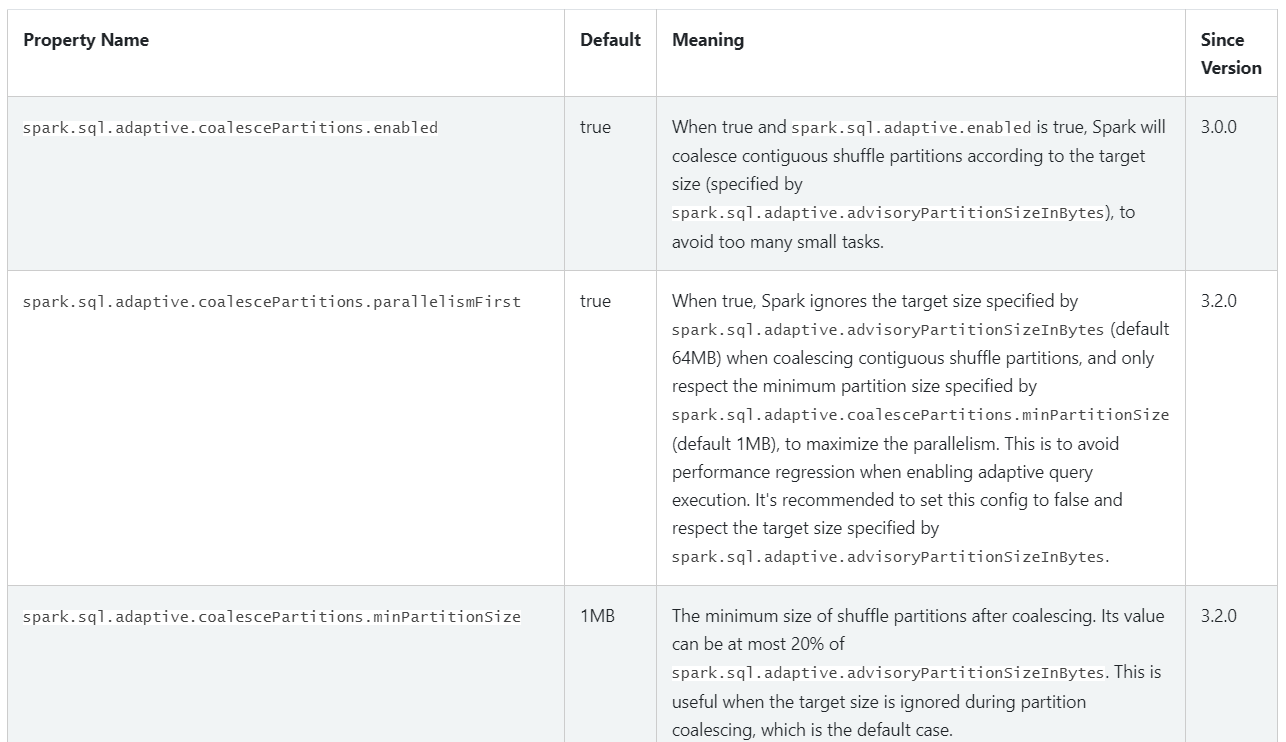

1 | 在这里面还有一个参数大家可以了解一下: |
1 | 接下来我们通过一个具体的案例来演示一下。 |
1 | 开发代码:AQECoalescePartitionsScala |
scala
spark sql shuffle默认分区数
1 | package com.imooc.scala.sql |
1 | 我们可以把前面提到的那几个核心参数在代码中验证一下,因为不同的Spark版本中这些参数可能会有一些差异,通过下面这几行代码可以打印出来spark中这些参数的默认值。 |
1 | 为了方便一些,我们就直接在本地idea中运行代码。 |
1 | 然后到任务界面中查看任务执行情况: |
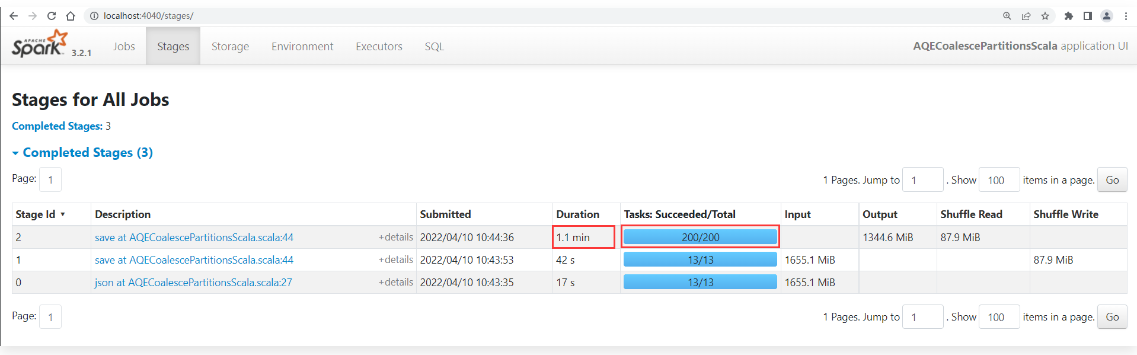
1 | 可以点进去看一下,每个task大致处理450KB的数据。 |
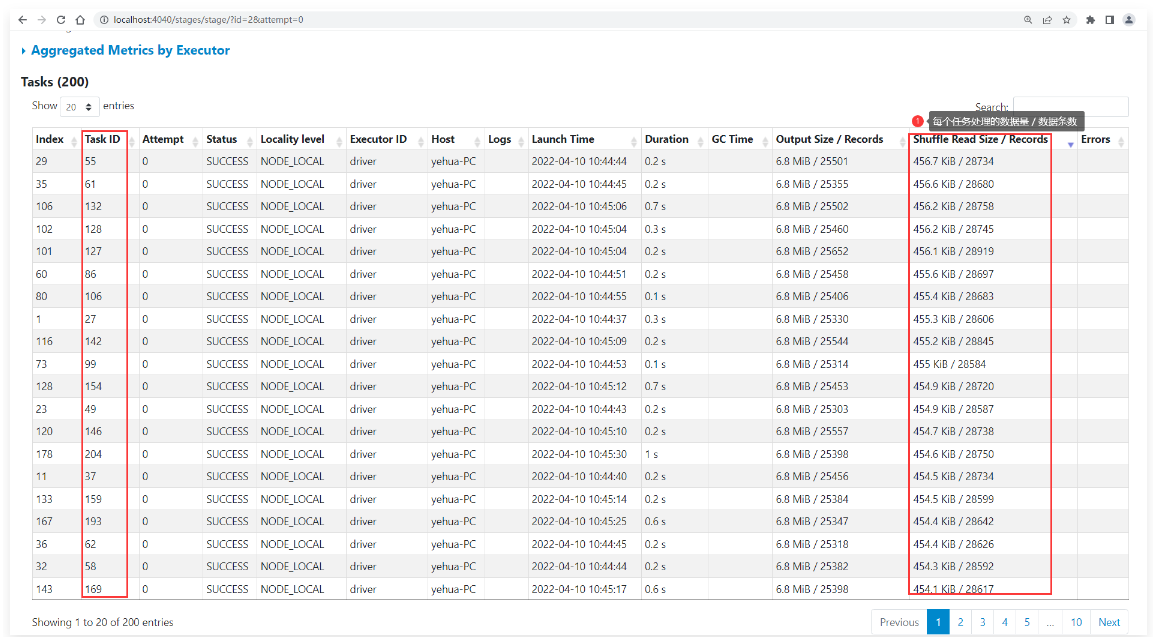
1 | 这个时候其实拆分出这么多的分区只会降低计算效率,因为数据量太小了。 |
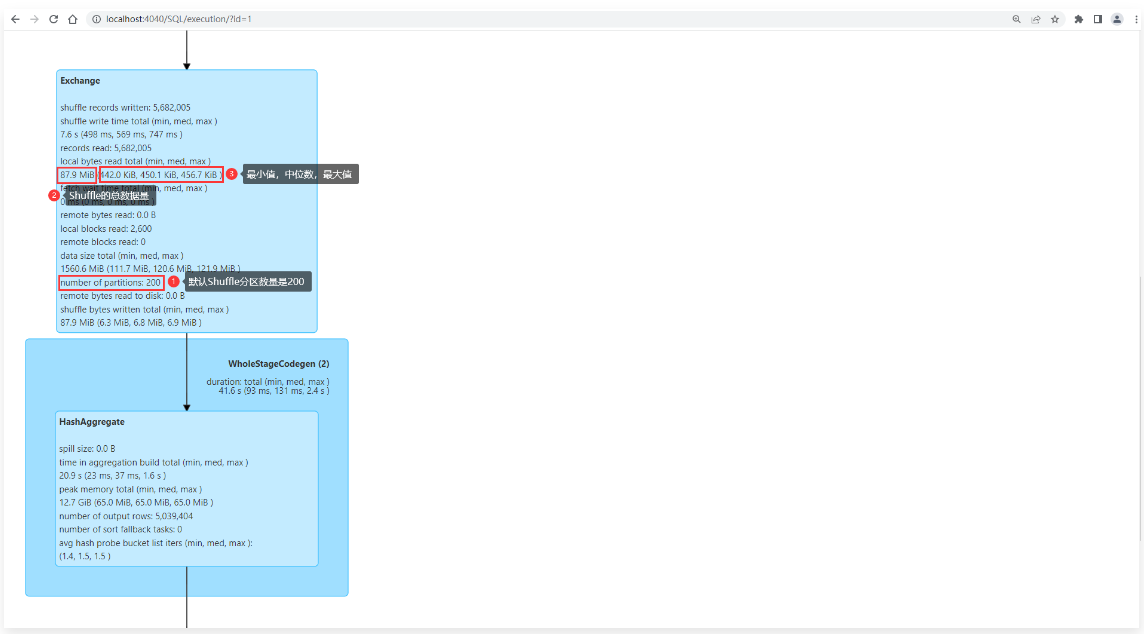
1 | 这两个地方都可以查看: |
手工指定shuffle分区数量
1 | //获取SparkSession,为了操作SparkSQL |
1 | 执行代码,到任务界面中查看效果。 |
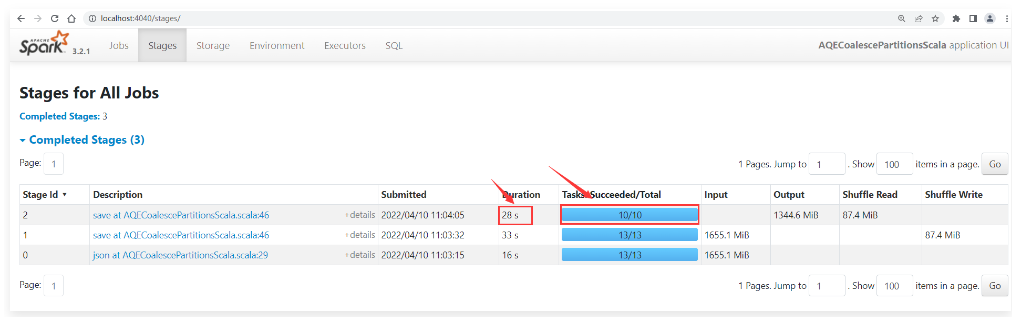
1 | 此时发现在Stage中产生了10个Task,因为我们在代码中设置了Shuffle分区数量是10,所以产生了10个Task,这个是正确的。 |
AQE&自适应调整shuffle分区
1 | 所以从Spark3.0开始,引入了AQE机制,可以实现自适应调整Shuffle分区数量。 |
1 | //获取SparkSession,为了操作SparkSQL |
1 | 执行代码,到任务界面中查看效果 |
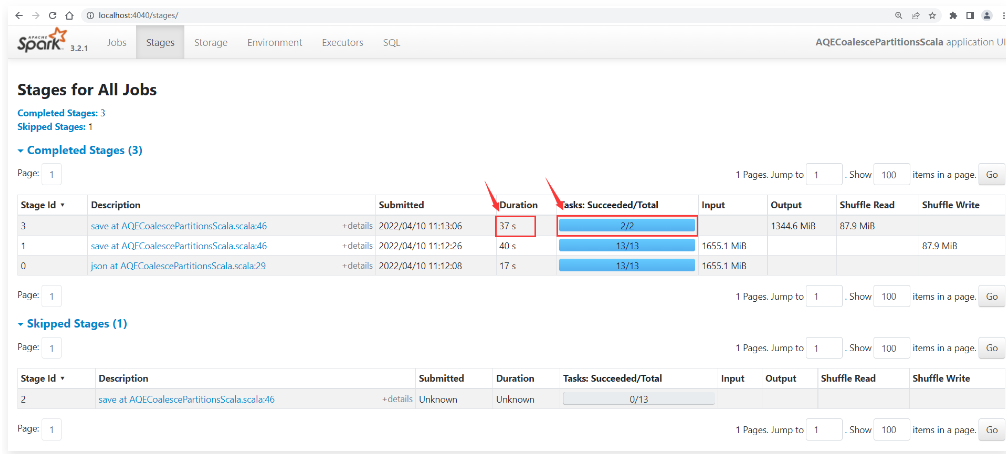
1 | 此时发现Stage中的task数量是2,这个就表示经过自适应调整Shuffle分区数量之后,将分区数量调整成了2个。最终产生2个Task。整个Stage的执行耗时为37秒 |
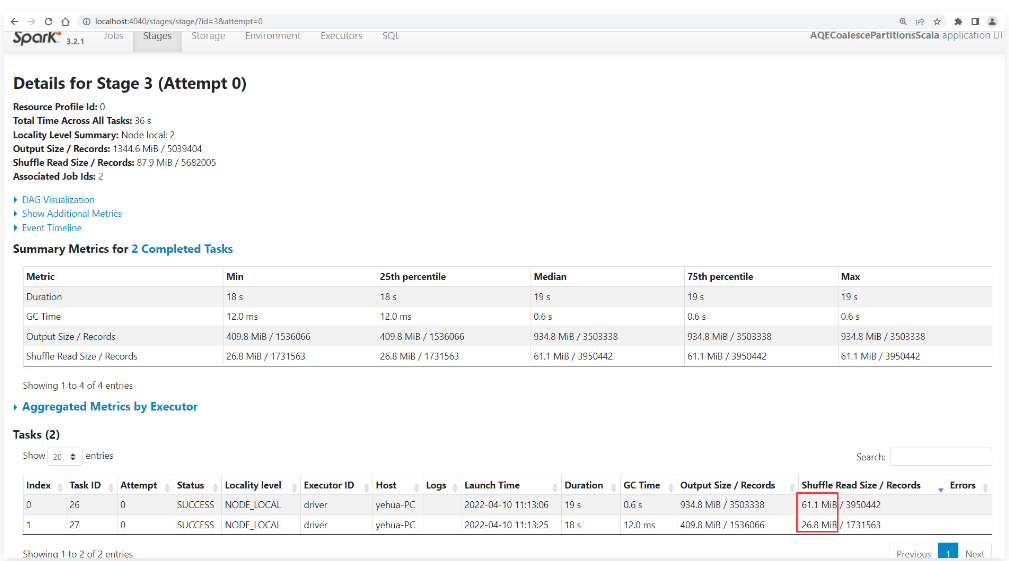
1 | 其中一个task处理61M的数据,另外一个task处理26M的数据。 |
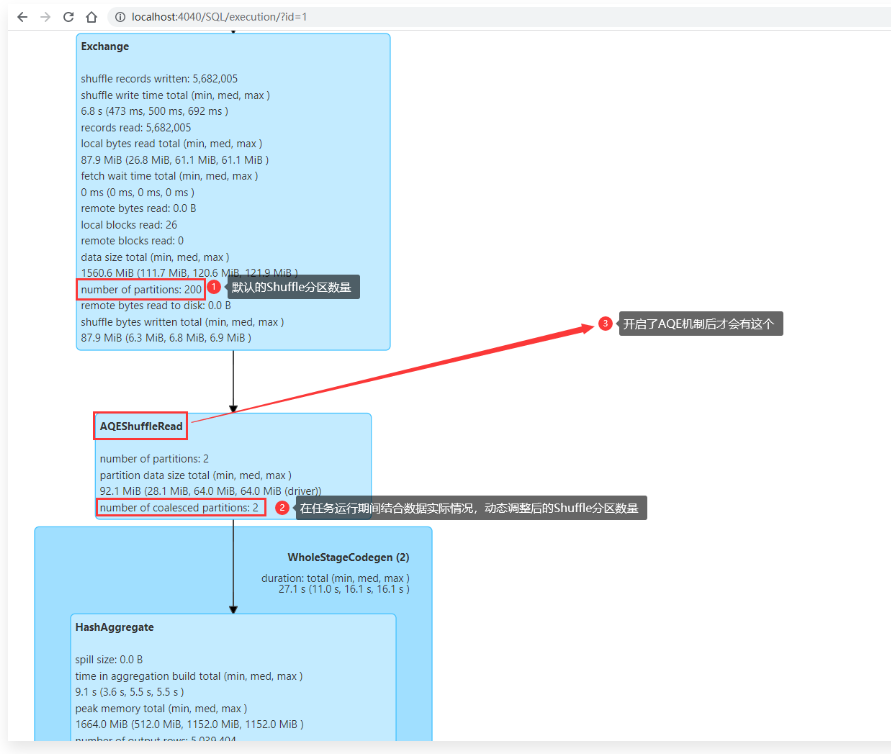
1 | 大家在这里可能会有一个问题: |
调整一下默认的Shuffle分区大小
1 | 接下来我们调整一下默认的Shuffle分区大小,改为30 M,看一下此时任务会产生多少个Shuffle分区。 |
1 | 执行程序,到任务界面查看效果: |
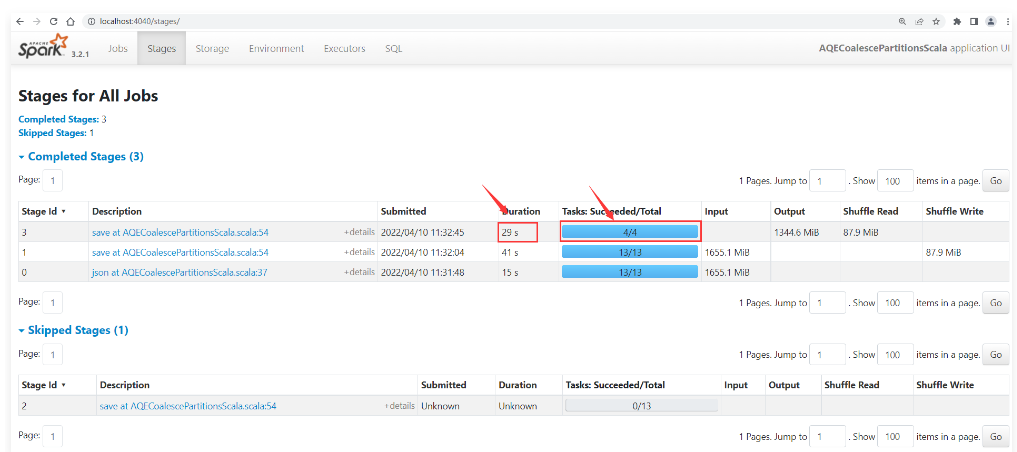
1 | 此时发现在Stage中产生了4个Task,耗时为29秒。 |
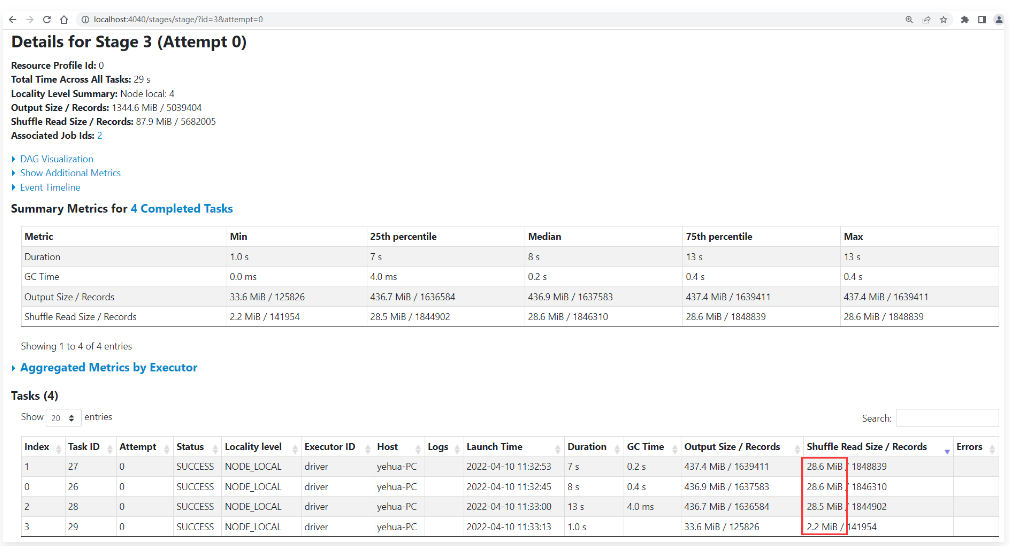
1 | 最终产生了3个28M的分区,1个2M的分区,说明我们修改的spark.sql.adaptive.advisoryPartitionSizeInBytes这个参数是生效了。 |
动态调整Join策略
1 | Spark中支持多种Join 策略,其中 BroadcastHashJoin的性能通常是最好的,但是前提是参加Join的其中一张表的数据能够存入内存。 |
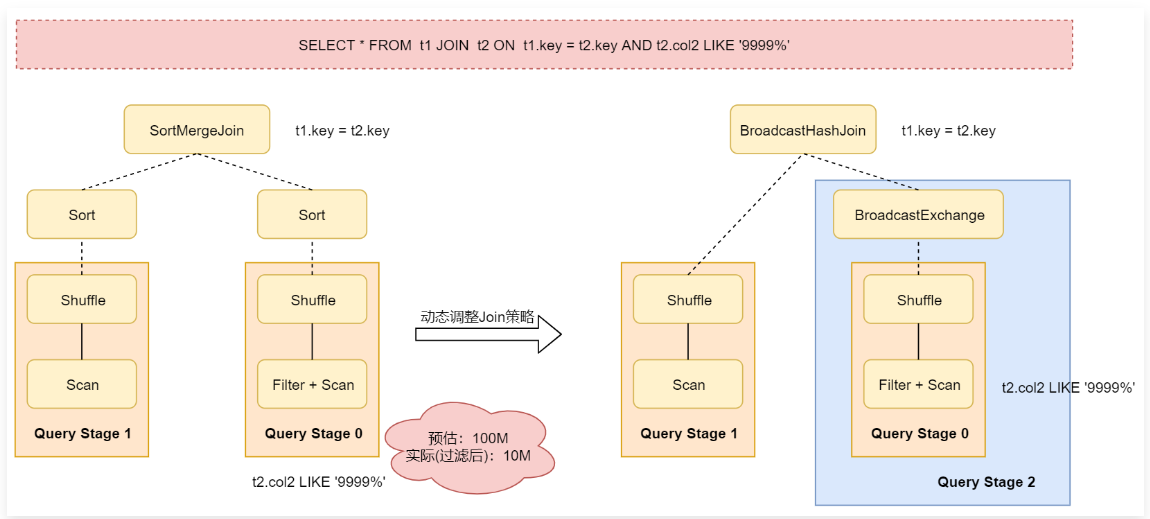
1 | 从这个图里面可以看到,对表t2进行过滤之后的数据大小比预估值小得多,并且小到足以进行广播,因此在重新优化之后,之前静态生成的SortMergeJoin策略就会被转换为BroadcastHashJoin策略了。 |
1 | spark.sql.adaptive.autoBroadcastJoinThreshold:这个参数没有默认值,通过这个参数可以控制允许广播的表的最大值。当两个表进行join的时候,如果一个表比较小,可以通过广播机制广播出去,这样就可以把本来是reduce端的join,改为map端的join,提高join效率。如果把这个参数的值设置为-1,表示禁用自动广播策略。如果我们没有给这个参数设置值,则默认会使用spark.sql.autoBroadcastJoinThreshold参数的值,这个参数的值默认是10M。那也就是说当一个表中的数据小于10M的时候在这里支持将这个表广播出去。 |
1 | 下面我们通过一个具体案例演示一下: |
scala
关闭自适应查询
1 | package com.imooc.scala.sql |
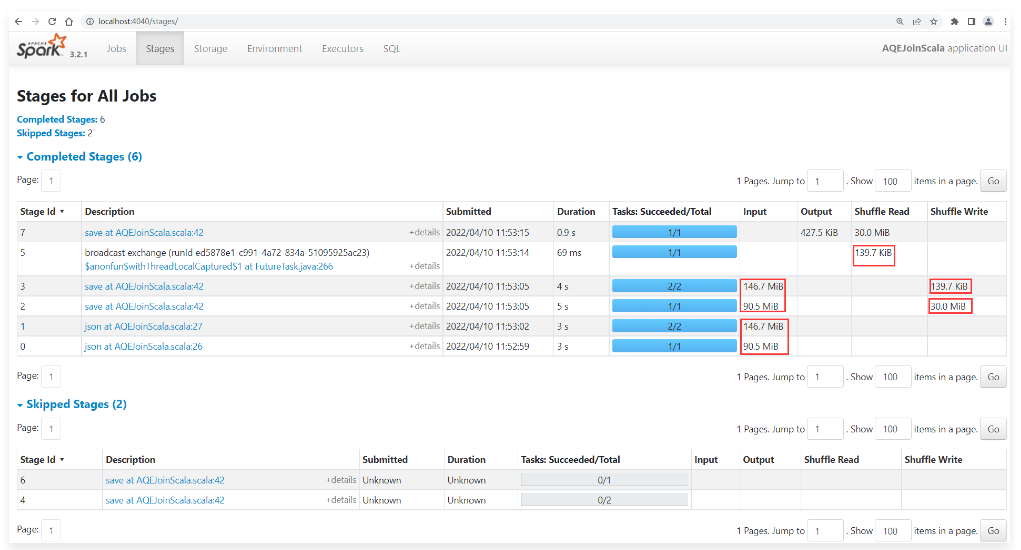
1 | 查看任务界面信息: |
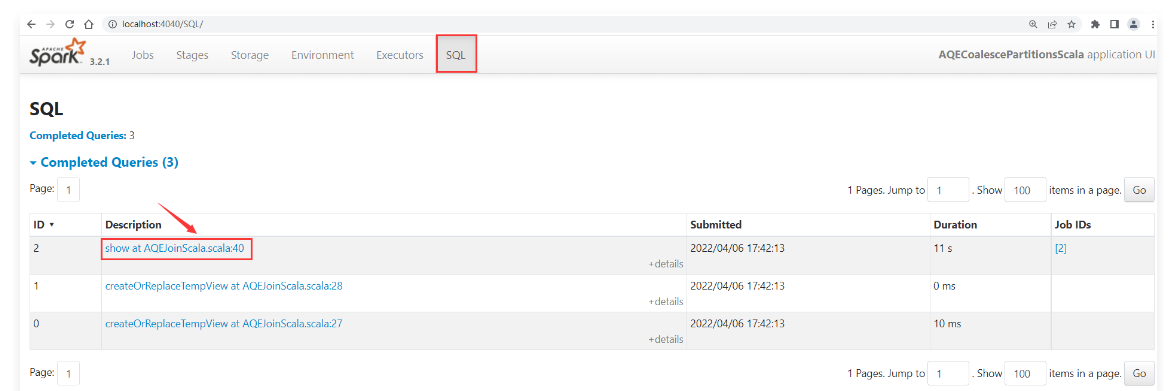
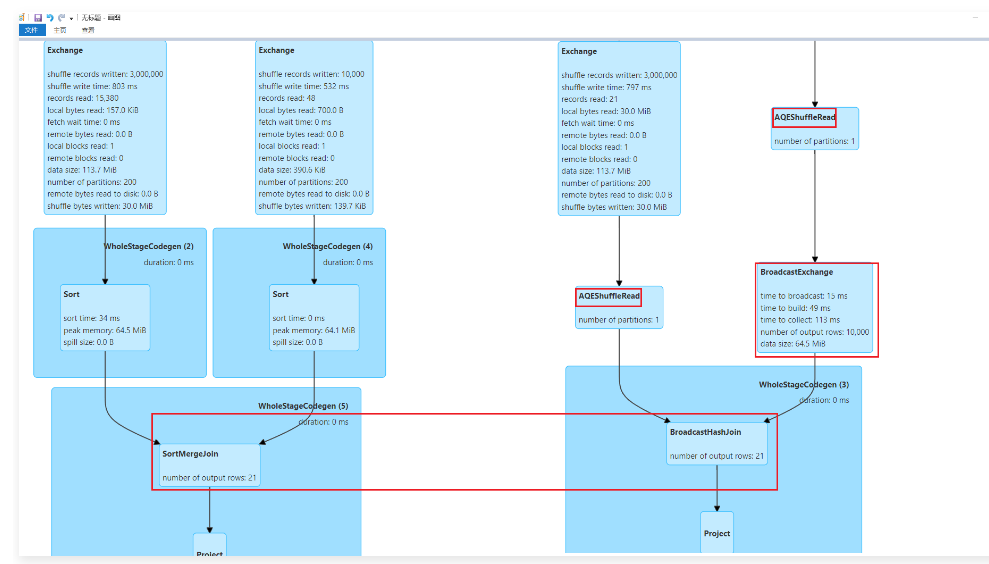
1 | 从下面这个图里面可以看出来,此时JOIN的时候使用的是SortMergeJoin策略。 |
1 | 这个策略是任务一开始的时候就指定好的,因为前期任务无法真正知道过滤后的t2表有多大,原始的t2表有146M,原始的t1表有90M,所以不满足广播策略的条件。 |
开启动态join
1 | 接下来修改代码,开启动态调整Join策略,其实也就是开启自适应查询执行机制。 |
1 | 执行代码,查看任务界面效果: |
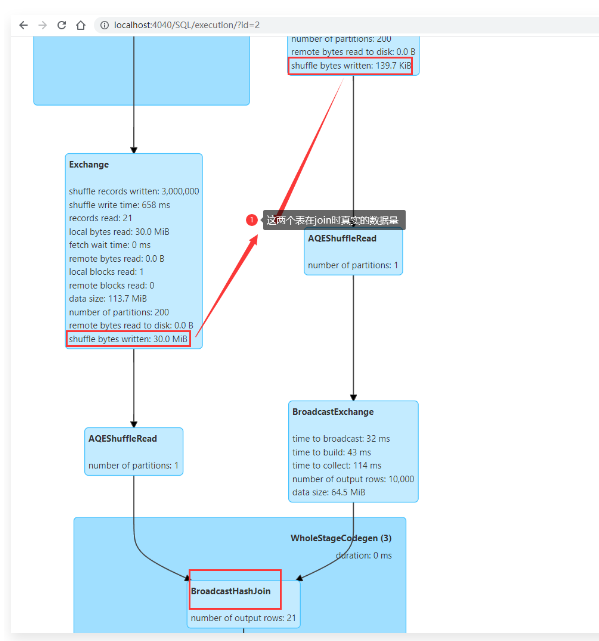
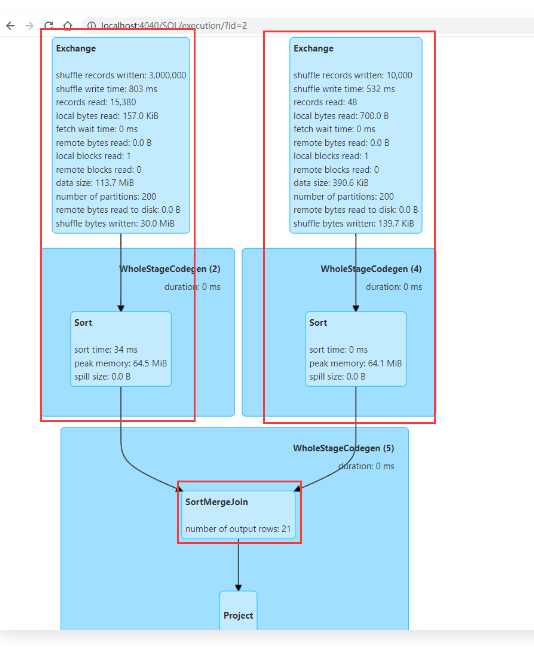
1 | 因为针对t2表,通过like过滤之后剩下的真实数据只有139KB,这个数据大小是小于10M的,可以广播出去提高Join的效率。 |
1 | 针对这两种情况的执行效果进行对比,如下图所示,开启了自适应查询执行机制之后,会在运行期间获取到t2表过滤后的真实数据,从而修改之前的执行策略。 |
1 | 注意:当我们把spark.sql.adaptive.autoBroadcastJoinThreshold参数设置为-1的时候,可以禁用sparksql中的自动广播机制,就算开启了自适应查询执行机制,也无法转换为BroadcastHashJoin策略。 |
1 | 执行代码,查看任务界面效果: |
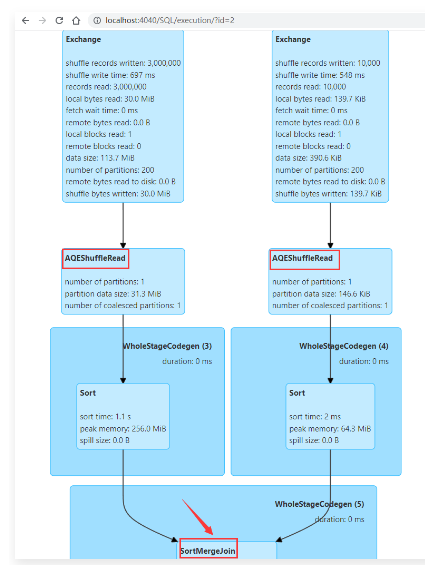
1 | 此时发现就算是开启了自适应查询执行机制,依然还是使用的SortMergeJoin策略。 |
动态优化倾斜的 Join
1 | 在进行Join操作的时候,如果数据在多个分区之间分布不均匀,很容易产生数据倾斜,如果数据倾斜比较严重会显著降低计算性能。 |
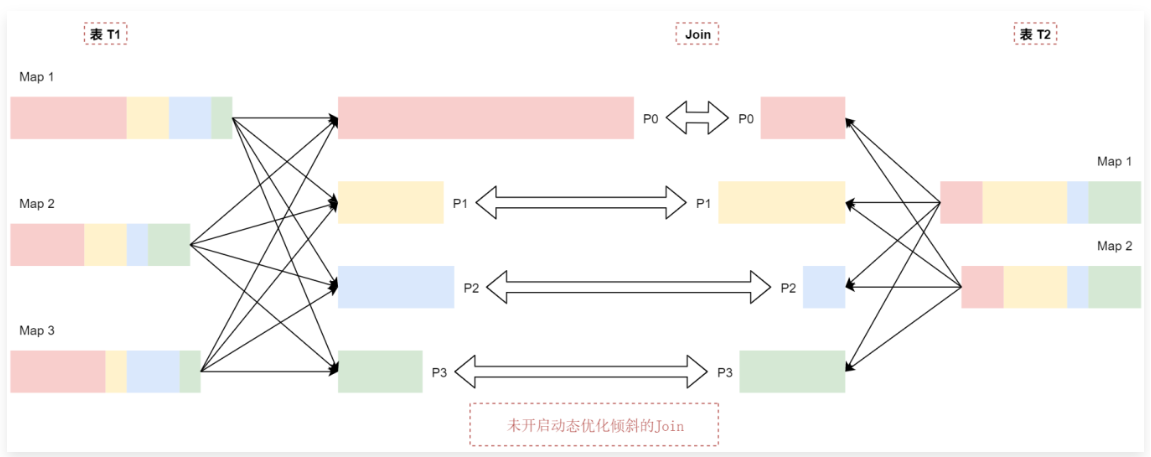
1 | t1表中p0分区的数据比p1\p2\p3这几个分区的数据大很多,可以认为t1表中的数据出现了倾斜。 |
1 | 动态优化倾斜的 Join机制会把P0分区切分成两个子分区P0-1和P0-2,并将每个子分区关联到表t2的对应分区P0,看这个图: |
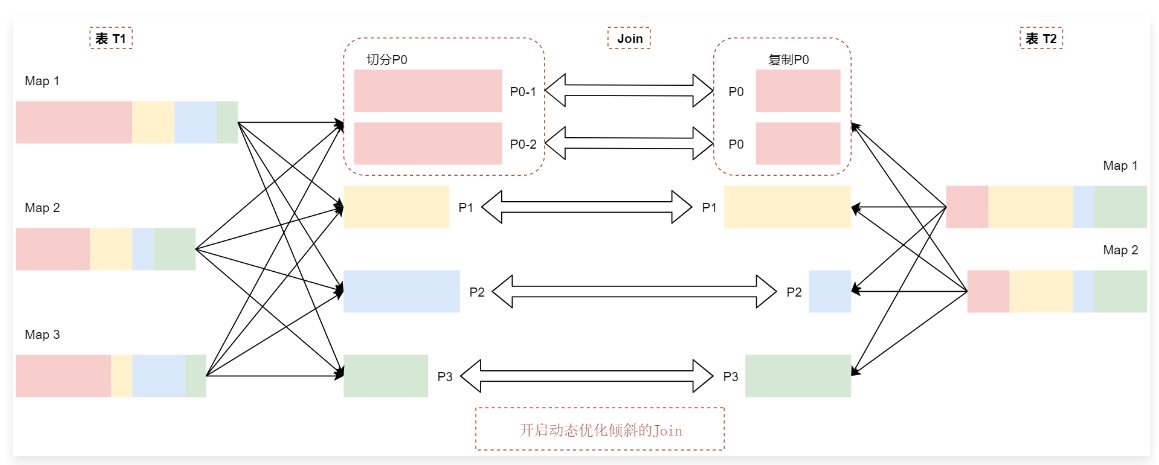
1 | t2表中的P0分区会复制出来两份相同的数据,和t1表中切分出来的P0分区的数据进行Join关联。 |
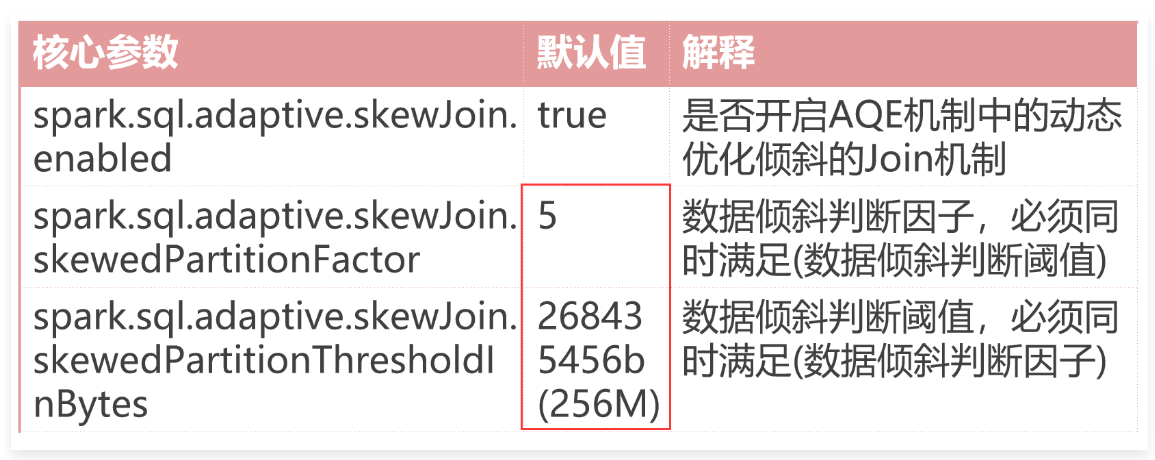
1 | 核心参数 默认值 解释 |
1 | spark.sql.adaptive.skewJoin.enabled:默认值是true,表示默认开启AQE机制中的动态优化倾斜的Join机制。 |
1 | 如果Shuffle中的一个分区的大小大于skewedPartitionFactor这个因子乘以Shuffle分区中位数的值,并且这个分区也大于skewedPartitionThresholdInBytes这个参数的值,则认为这个分区是倾斜的。 |

1 | 如果分区A中的数据大小 大于skewedPartitionFactor * 分区大小的中位数。 |
scala
关闭动态优化倾斜的Join
1 | 下面我们来根据一个案例具体分析一下: |
1 | package com.imooc.scala.sql |
1 | 运行程序,到任务界面中查看运行效果。 |
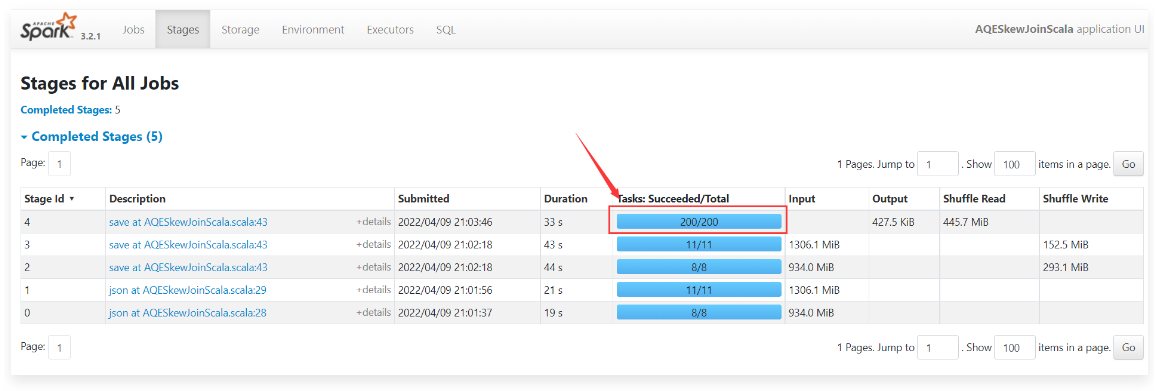
1 | 但是仔细查看这200个任务,发现其中有一个任务处理的数据量非常大,在153M左右。其他的任务处理的数据量很小,都在1.5M左右。从这里可以看出来这个Join操作在执行的时候出现了数据倾斜。 |
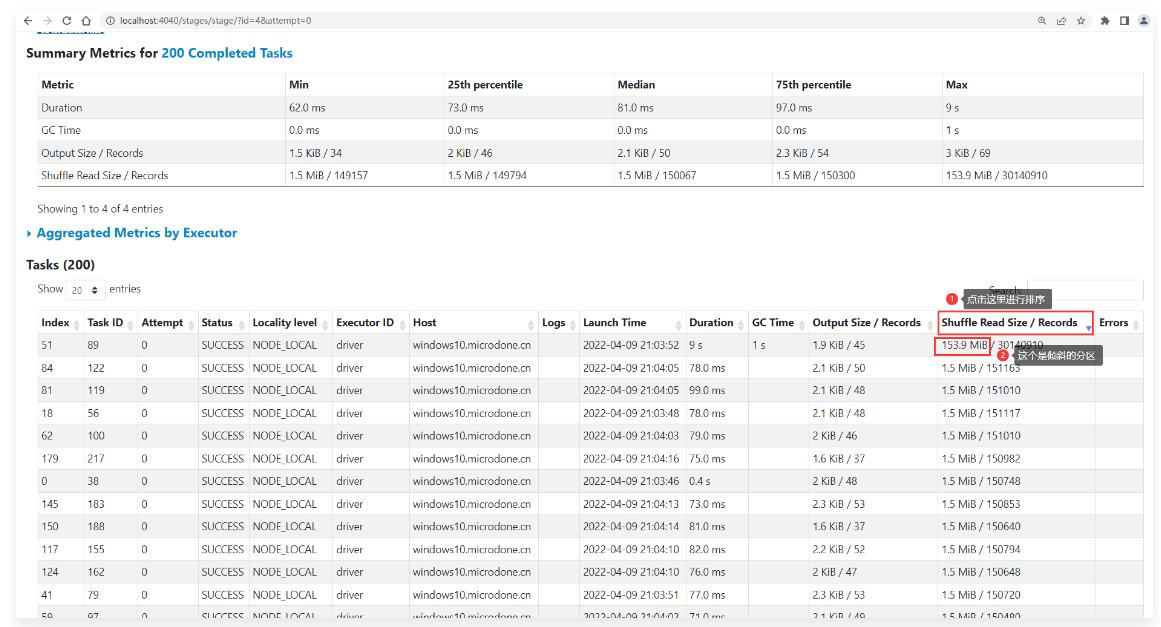
开启动态优化倾斜的Join
1 | 针对这个任务而言,想要提高计算效率,需要把这个倾斜的分区中的数据进行拆分,拆分成多个子任务去执行,这样就可以了。 |
1 | 重新执行程序,到任务界面中查看效果: |
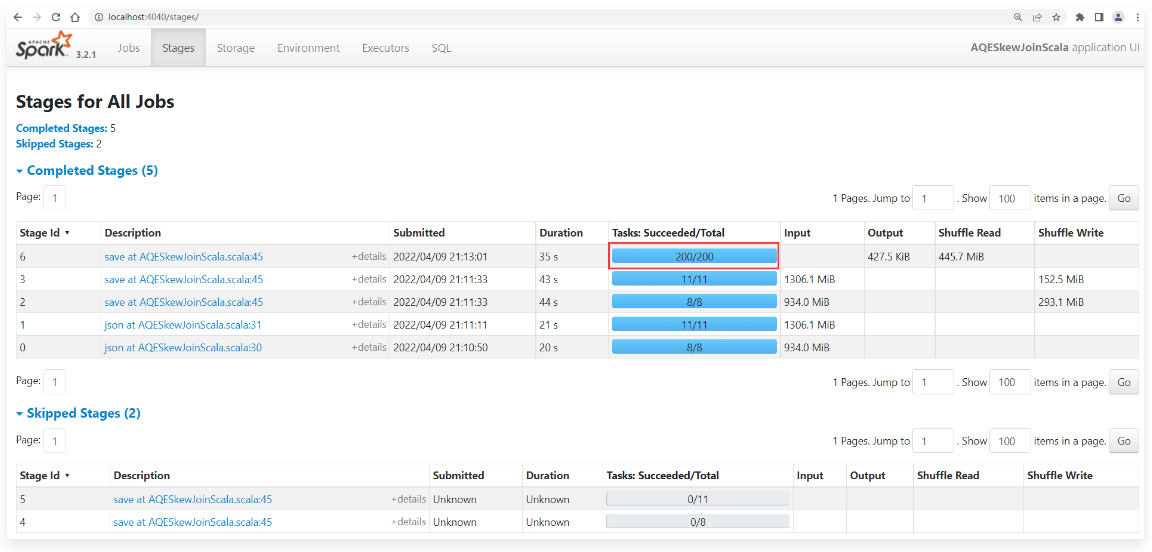
1 | 进入这个Stage查看详细信息: |
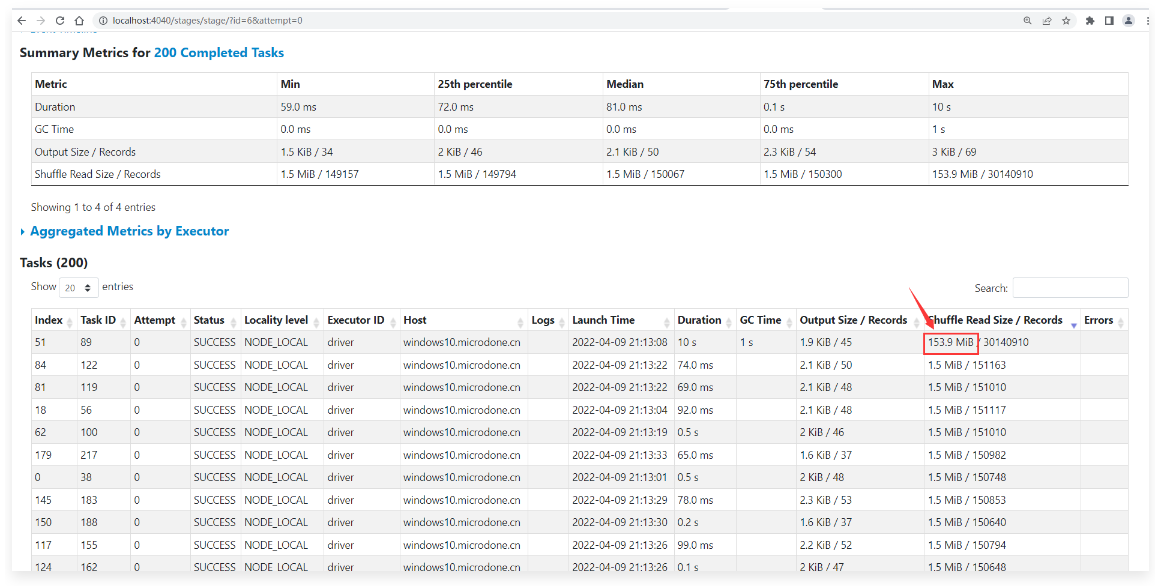
1 | 为什么动态优化倾斜的 Join这个功能没有生效呢? |
1 | 如果我们开启了动态优化倾斜的 Join这个功能,并且确实有数据倾斜了,但是没有真正触发执行,那说明这个倾斜的数据没有满足这2个参数的指标, |

1 | 只有这2个条件都满足了,才认为数据倾斜了。 |
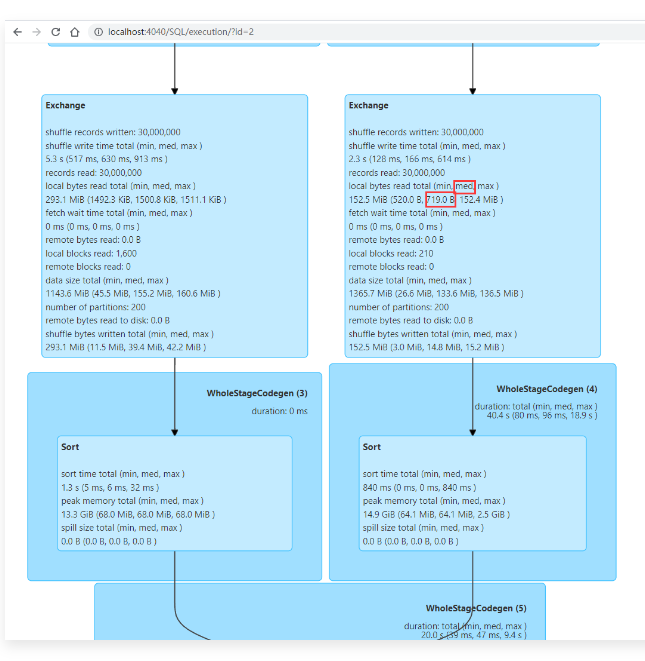
1 | 从图中可以看出来分区大小的中位数就是719字节。 |
1 | val sparkSession = SparkSession |
1 | 重新执行程序,到任务界面中查看效果: |
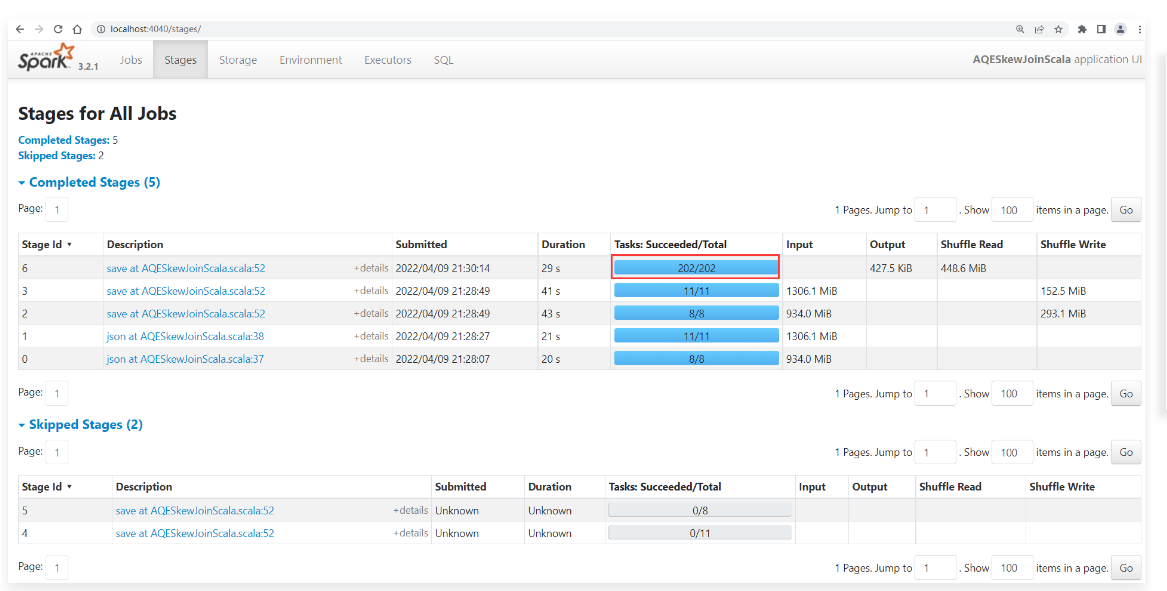
1 | 点击查看这个Stage的详细信息。 |
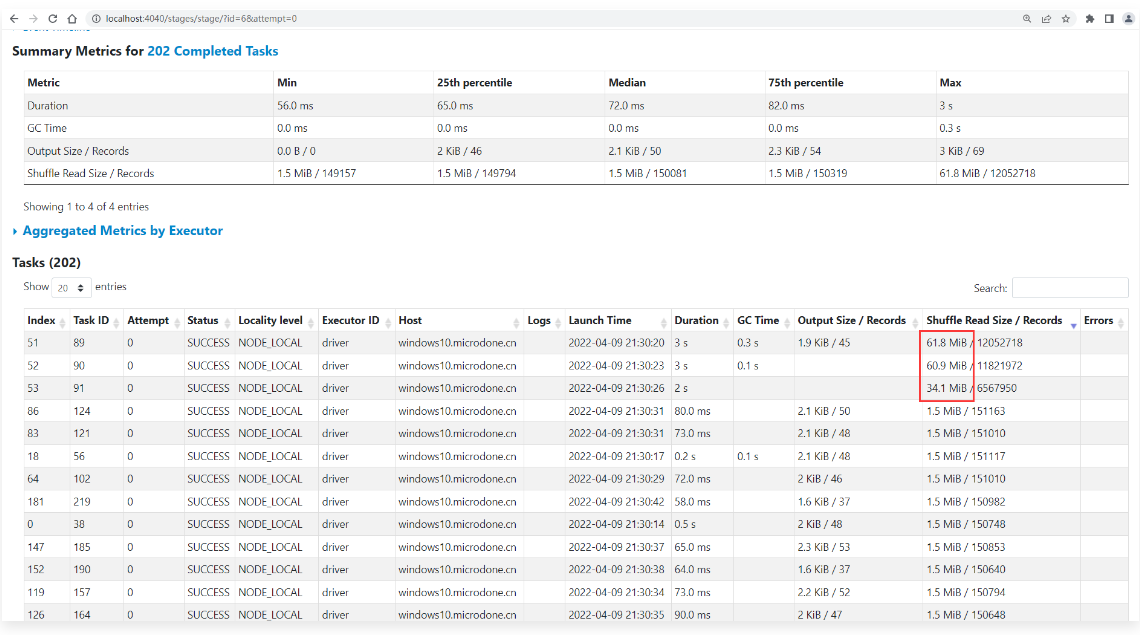
1 | 当然了,如果感觉这样拆分还是有点大,则可以对应的调整advisoryPartitionSizeInBytes参数的值,这个参数的值越小,拆分出来的分区就越多,但是太多了也不好,那样就是很多小任务了。 |
advisoryPartitionSizeInBytes大于skewedPartitionThresholdInBytes
1 | 注意:如果我在这里把advisoryPartitionSizeInBytes参数的值设置的比实际倾斜的分区还要大,那么此时会出现什么样的效果呢? |
1 | //获取SparkSession,为了操作SparkSQL |
1 | 重新执行程序,到任务界面中查看效果: |
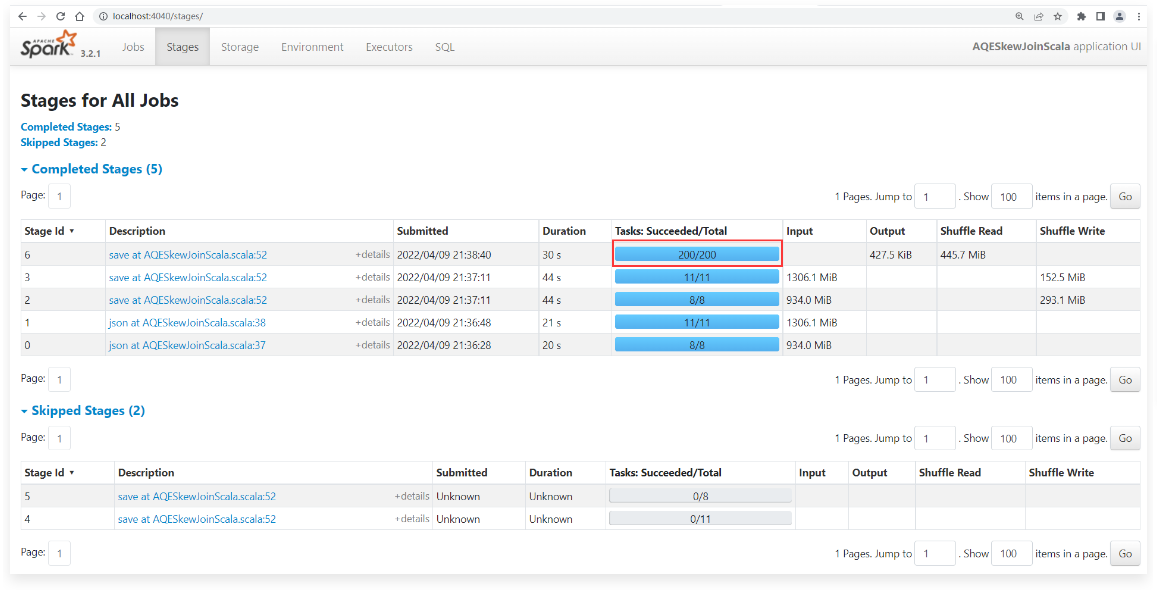
1 | 这个时候实际上动态优化倾斜的Join这个策略是被触发了,只是因为对这个倾斜的分区进行切分的时候出现了问题。 |
1 | 最后,我们把这个自适应调整Shuffle分区数量这个策略也打开,因为我们这里面其实是有很多小任务的,所以打开这个策略之后,是可以合并一些分区的,这样是可以提高效率的。 |
1 | //获取SparkSession,为了操作SparkSQL |
1 | 重新执行程序,到任务界面中查看效果: |
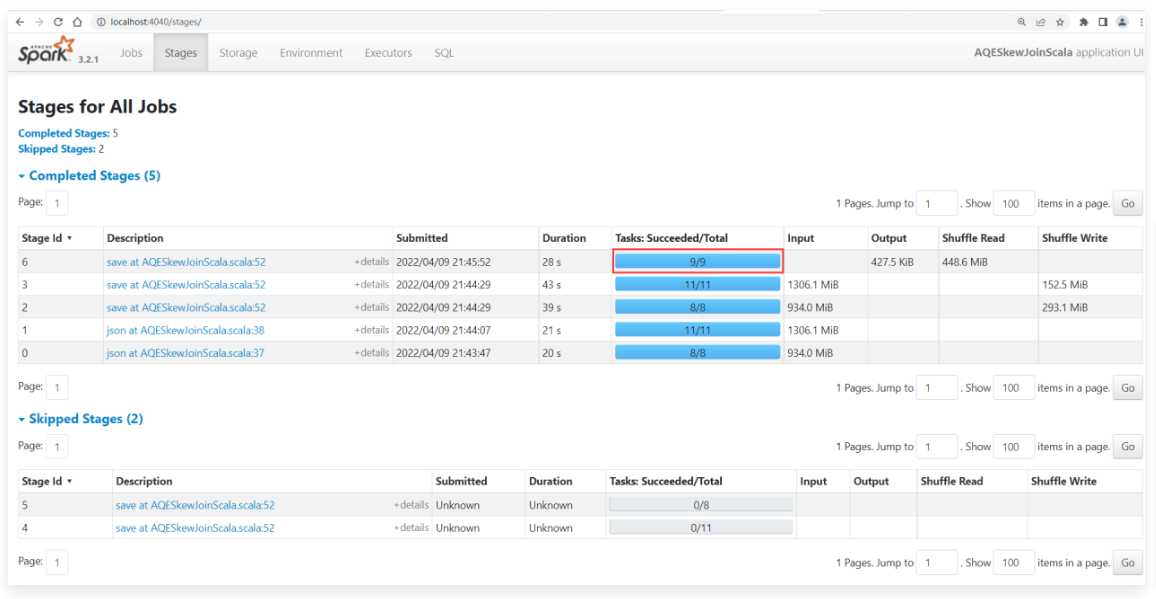
1 | 点进去查看详细信息: |
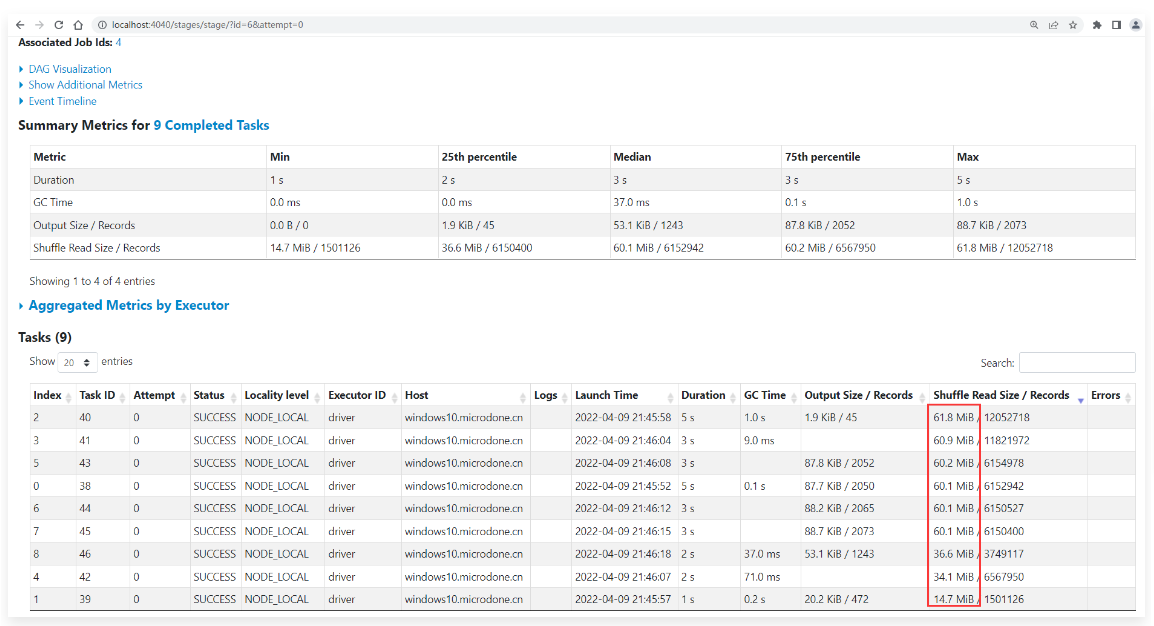
1 | 这就是自适应调整Shuffle分区数量和动态优化倾斜的Join功能结合在一起的效果。 |
总结
1 | 通过减少查询优化对静态统计的依赖,AQE 解决了 Spark 基于成本优化的最大难题之一:统计信息收集开销和估计精度之间的平衡。 |
动态分区裁剪
1 | 动态分区裁剪是什么意思呢? |
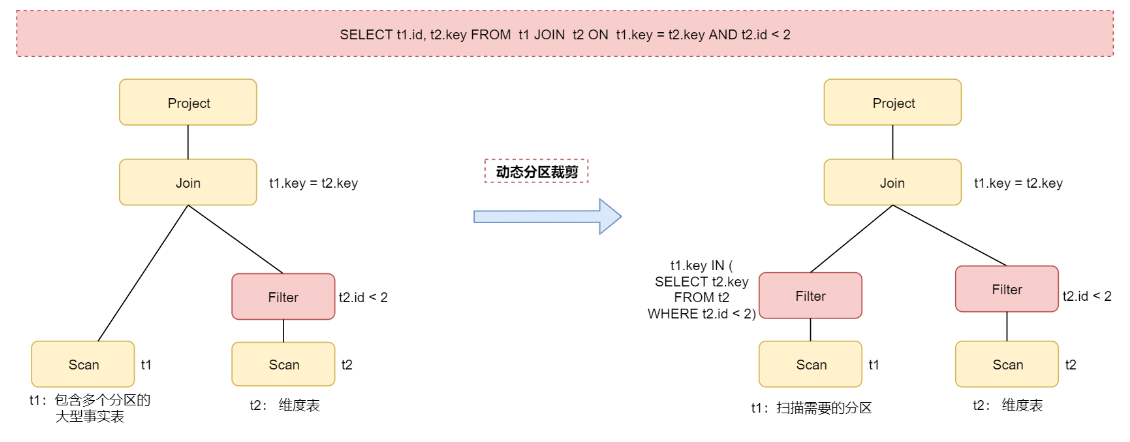
1 | 当我们在执行SELECT t1.id, t2.key FROM t1 JOIN t2 ON t1.key = t2.key AND t2.id <2这个Spark SQL 语句的时候。 |
1 | 如果在Join关联的时候能够提前对t1表中的数据也进行过滤,这样是可以极大提高Join效率的。 |
1 | 注意:这个动态分区裁剪操作默认是开启的,但是触发动态分区裁剪是需要一些条件的: |
1 | 针对动态分区裁剪主要包括1个核心参数,就是开启这个功能的参数。 |
scala
关闭动态分区裁剪功能
1 | 下面我们来通过一个案例验证一下效果。 |
1 | package com.imooc.scala.sql |
1 | 注意:这个程序如果在本地执行需要在windows中配置Hadoop的相关环境,比较麻烦,建议提交到YARN集群上执行。 |
1 | 打任务jar包。 |
1 | 开发任务提交脚本,并且提交任务。 |
1 | 注意:需要提前开启hadoop和spark的historyserver服务。 |
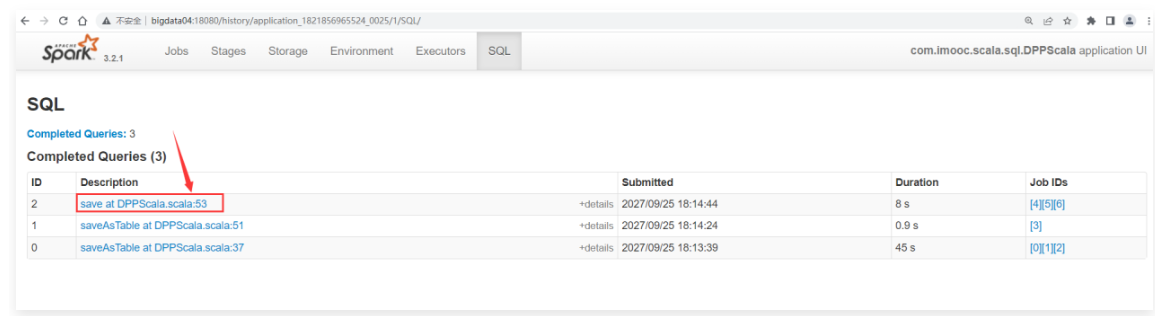
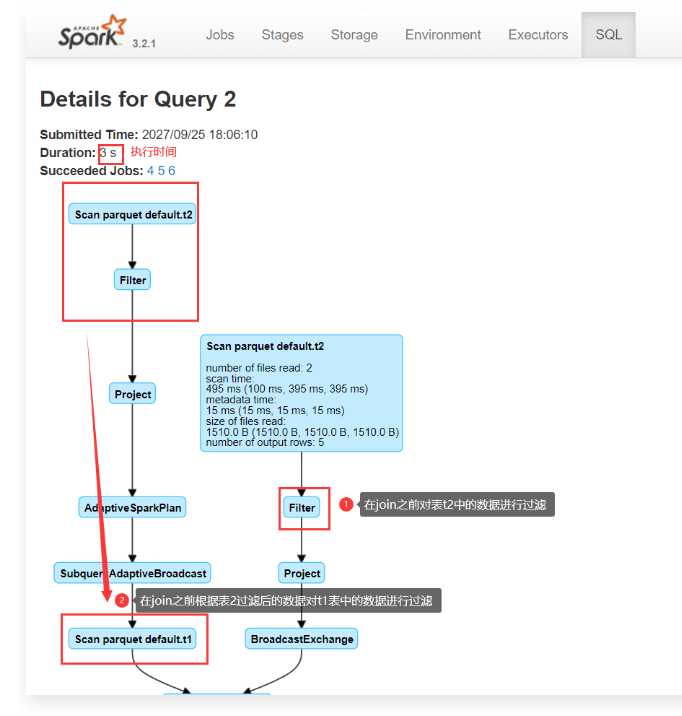
1 | 在join之前会先对t2中的数据进行过滤,然后和t1表中的数据进行join。 |
开启动态分区裁剪功能
1 | 接下来开启动态分区裁剪功能。 |
1 | 接下来重新打jar包 |
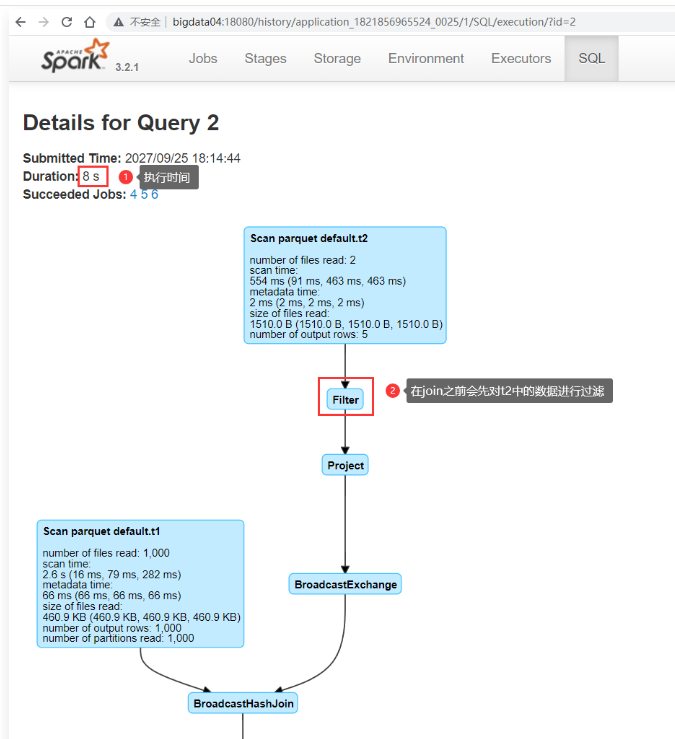
1 | 在join之前会对t2中的数据进行过滤,然后再根据t2过滤出来的数据对t1表中的数据进行过滤,最后对两个表中过滤后的数据进行join。 |
1 | 开启了动态分区裁剪的执行时间为3秒。之前没有开启动态分区裁剪时的时间是8s。所以说还是有很大性能提升的。 |
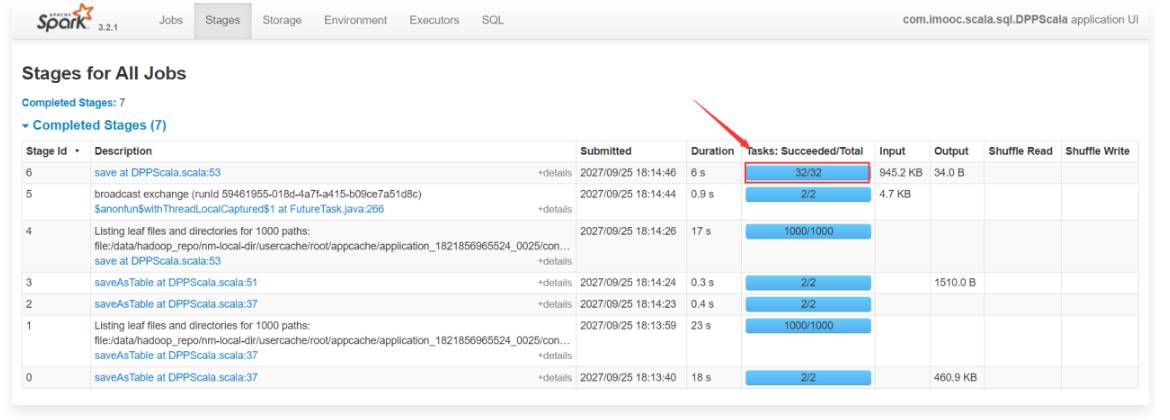
1 | 开启了动态分区裁剪的时候这个stage只需要启动2个task。 |
1 | 这就是动态分区裁剪功能的效果。 |
加速器感知调度
1 | 为了让Spark能够利用目标平台上的硬件加速器(例如目标平台上的GPU),Spark 3.0版本增强了已有的调度程序,使集群管理器可以感知到加速器,这就是加速器感知调度特性。 |
Catalog 插件 API
1 | Spark 2.x的时候新推出了DataSourceV2 API,主要是为了用来和外部数据存储进行交互。但是这个API缺少了关键的一个环节:对表的元数据进行操作(例如:创建、修改、删除表)。 |
1 | 不过Catalog API目前仍处于试验阶段,官方不建议在生产环境中使用。 |
支持Hadoop3.x / Java11 / Scala2.12
1 | Spark 3.x建议集成在Hadoop3.x版本之上。 |
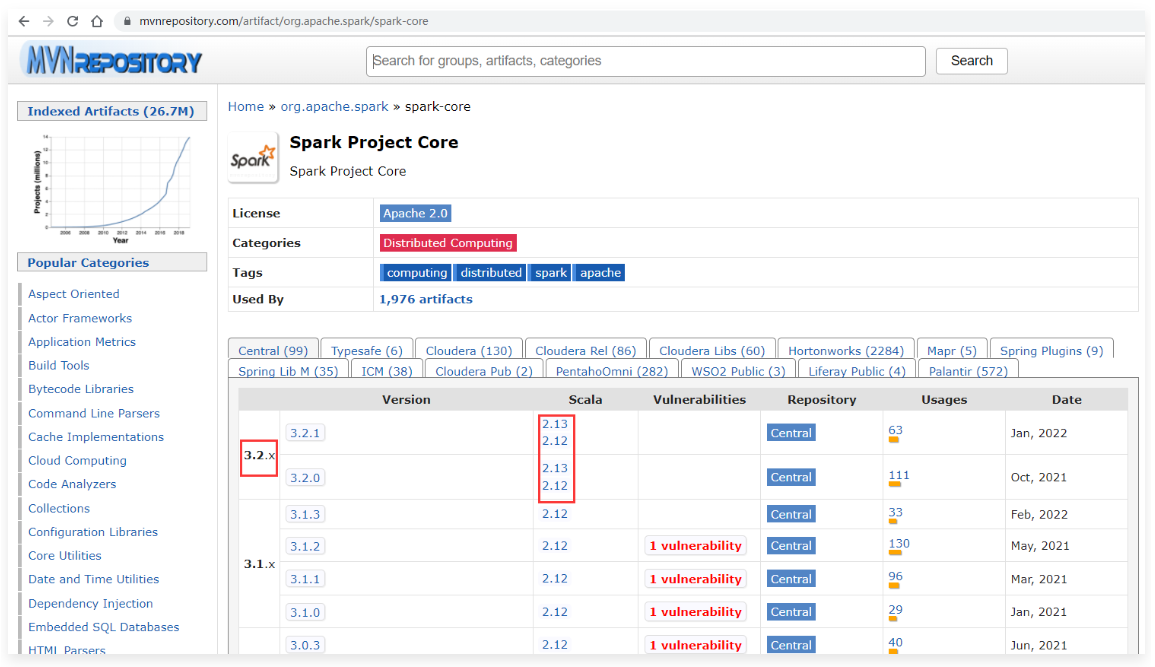
1 | 不过建议还是使用scala2.12版本,这个版本目前用的比较多。 |
更好的 ANSI SQL 兼容性
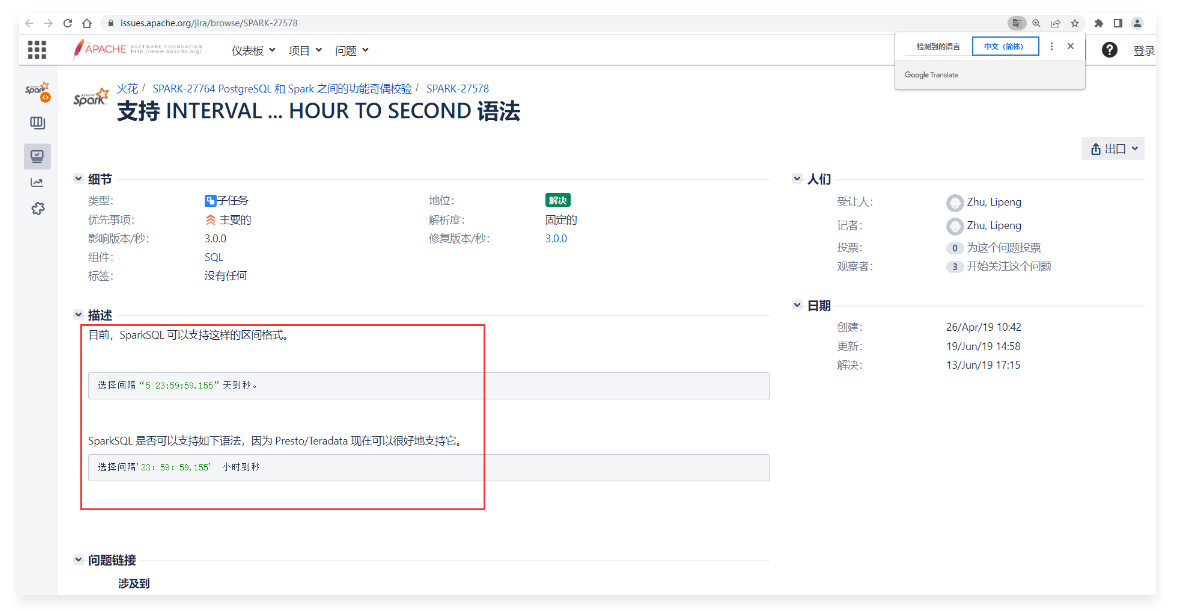
1 | PostgreSQL是目前比较先进的开源数据库之一,它支持SQL:2011中的大部分主要特性。SQL:2011中要求的179个功能,PostgreSQL至少符合160个。 |
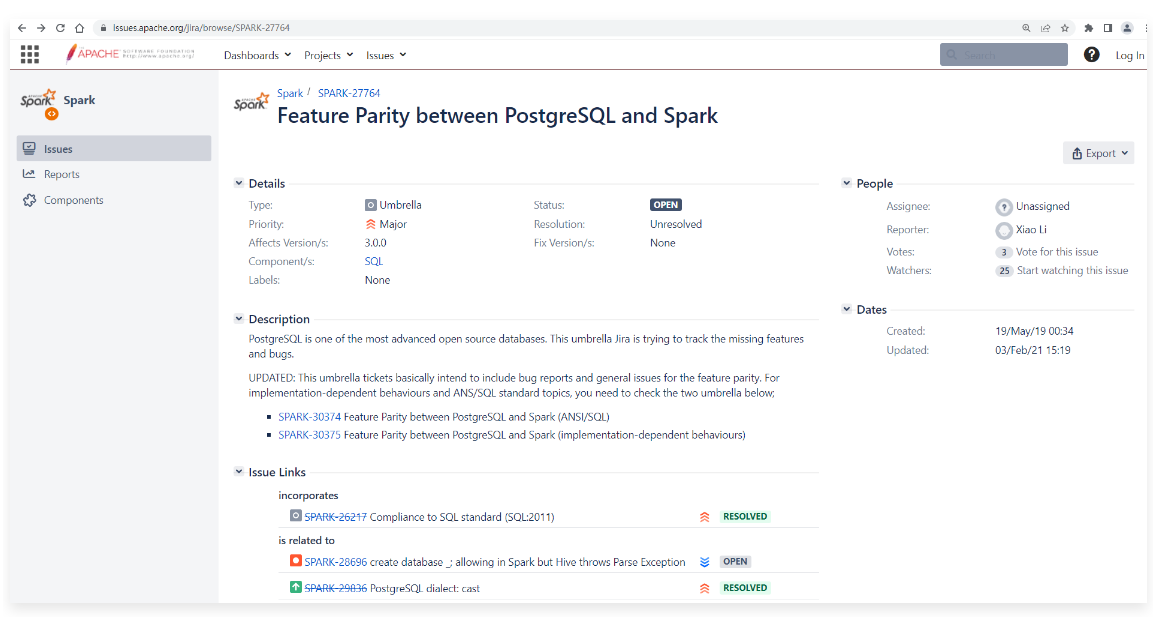
1 | 目前这个ISSUE处于OPEN打开状态,说明需要完善的功能还没有做完。 |
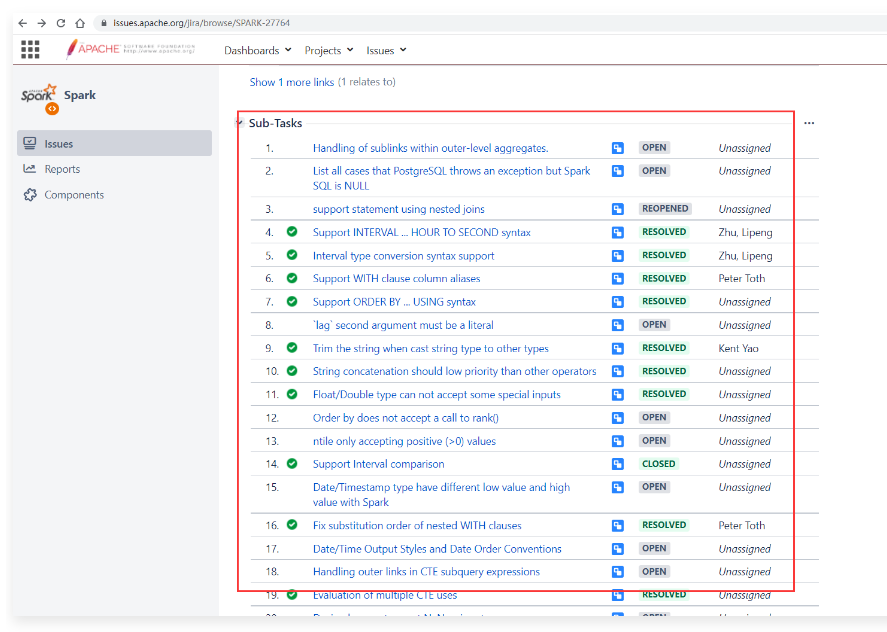
1 | 等这些子任务的状态都变为RESOLVED(解决)状态的时候说明完善工作都完成了。 |
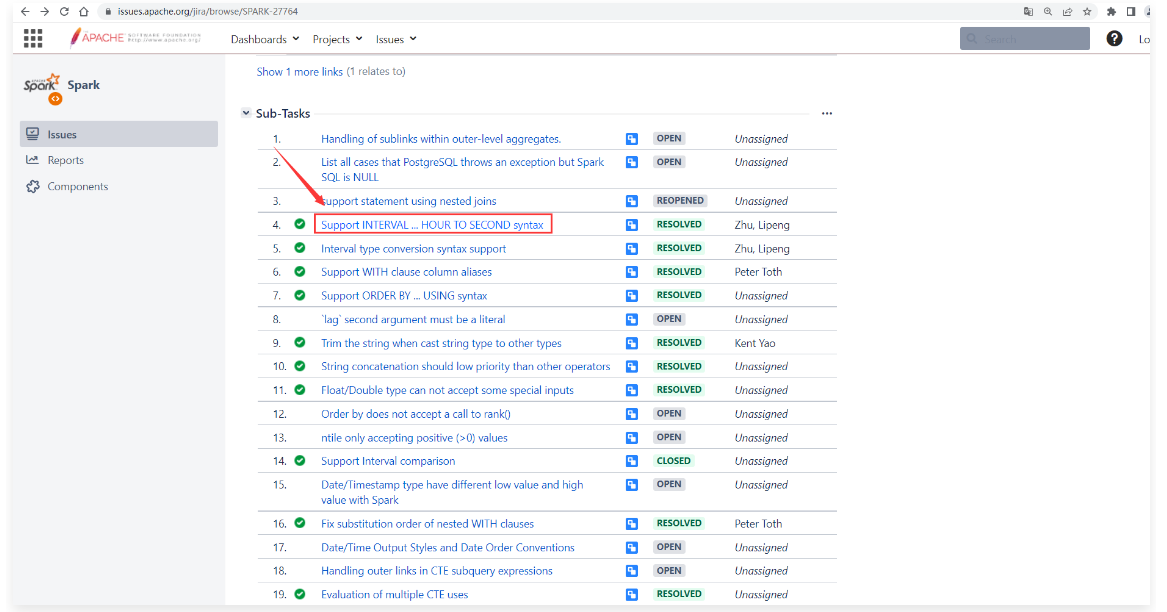
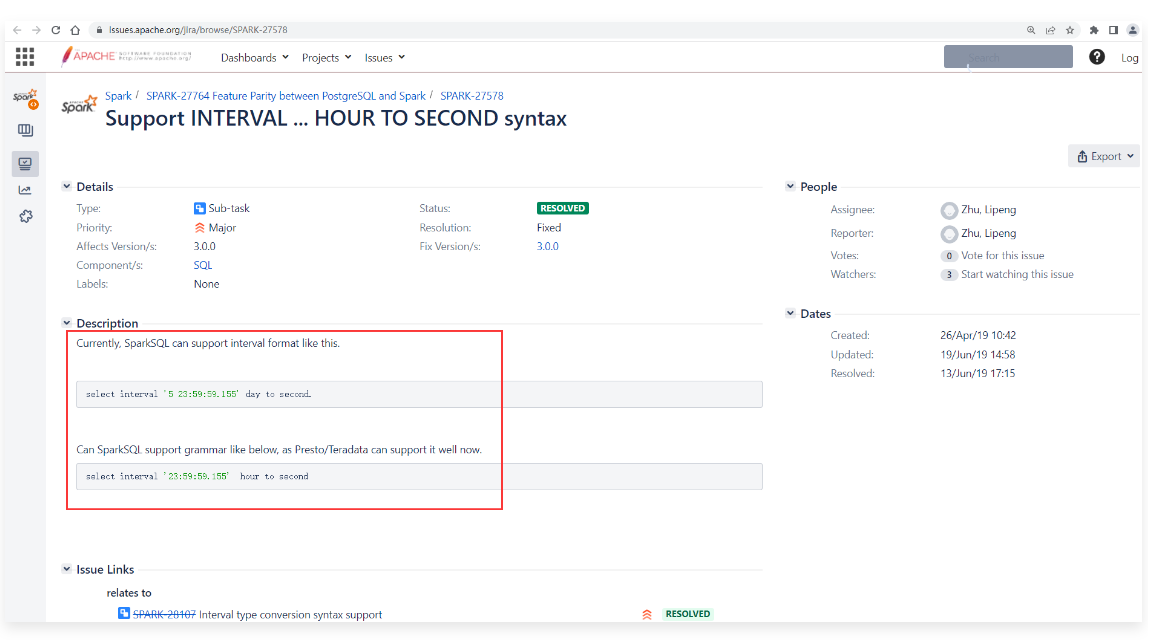
1 | 翻译为中文: |