大数据开发工程师-第十一周 sparkSQL快速上手使用
大数据开发工程师-第十一周 sparkSQL快速上手使用
智汇君大数据开发工程师-第十一周 sparkSQL快速上手使用
Spark SQL
1 | Spark SQL和我们之前讲Hive的时候说的hive on spark是不一样的。 |
SparkSession
1 | 要使用Spark SQL,首先需要创建一个SpakSession对象 |
创建DataFrame
1 | 使用SparkSession,可以从RDD、HIve表或者其它数据源创建DataFrame |
scala
1 | package com.imooc.scala.sql |
java
1 | package com.imooc.java.sql; |
1 | 由于DataFrame等于DataSet[Row],它们两个可以互相转换,所以创建哪个都是一样的 |
1 | 在Java代码中将DataSet[Row]转换为DataFrame |
DataFrame常见算子操作
1 | 下面来看一下Spark sql中针对DataFrame常见的算子操作 |
1 | printSchema() |
scala
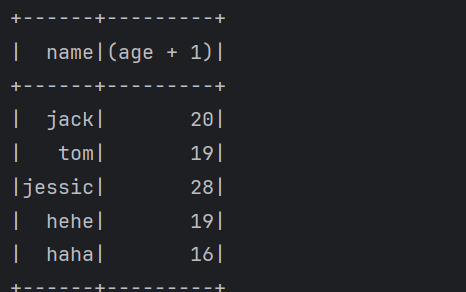
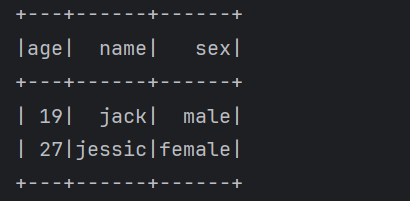
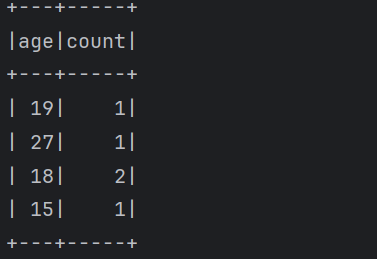
1 | 下面来使用一下这些操作 |

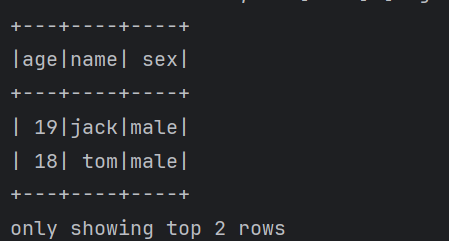
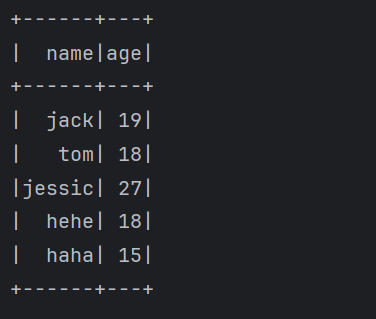
java
1 | package com.imooc.java.sql; |
1 | 这些就是针对DataFrame的一些常见的操作。 |
DataFrame的sql操作
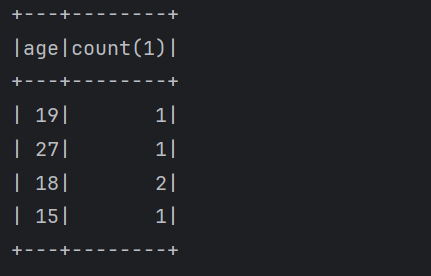
1 | 想要实现直接支持sql语句查询DataFrame中的数据 |
scala
1 | package com.imooc.scala.sql |
java
1 | package com.imooc.java.sql; |
RDD转换为DataFrame
1 | 为什么要将RDD转换为DataFrame? |
反射方式
1 | 下面来看一下反射方式: |
scala
1 | package com.imooc.scala.sql |

java
1 | java代码值得注意下 |
1 | package com.imooc.java.sql; |
编程方式
1 | 接下来是编程的方式 |
scala
1 | package com.imooc.scala.sql |
java
1 | package com.imooc.java.sql; |
load和save操作
1 | 对于Spark SQL的DataFrame来说,无论是从什么数据源创建出来的DataFrame,都有一些共同的load和save操作。 |
1 | 注意:如果看不到源码,需要点击idea右上角的download source提示信息下载依赖的源码。 |
scala
1 | package com.imooc.scala.sql |
1 | 执行代码,查看结果,csv文件是使用逗号分隔的: |

java
1 | package com.imooc.java.sql; |
SaveMode
1 | Spark SQL对于save操作,提供了不同的save mode。 |
1 | 在LoadAndSaveOpScala中增加SaveMode的设置,重新执行,验证结果 |
1 | 执行之后的结果确实是追加到之前的结果目录中了 |
作业
1 | Spark SQL支持使用JDBC从关系型数据库(比如MySQL)中读取数据 |
内置函数
1 | Spark中提供了很多内置的函数, |











