大数据开发工程师-第九周 Hive扩展内容 常见数据存储格式的使用
大数据开发工程师-第九周 Hive扩展内容 常见数据存储格式的使用
智汇君大数据开发工程师-第九周 Hive扩展内容 常见数据存储格式的使用
数据存储格式
1 | 在最开始学习Hive的时候我们说到了,Hive没有专门的数据存储格式,默认可以直接加载文本文件TextFile,还支持SequenceFile、RCFile这些。 |
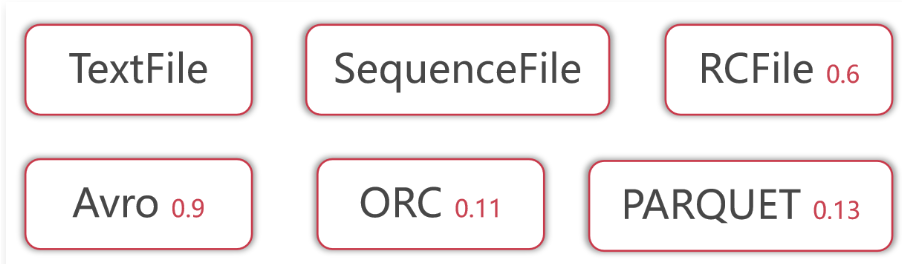
1 | 其中RCFile数据存储格式是从Hive 0.6版本开始支持的。 |
1 | 这些信息主要来源于Hive官网。 |
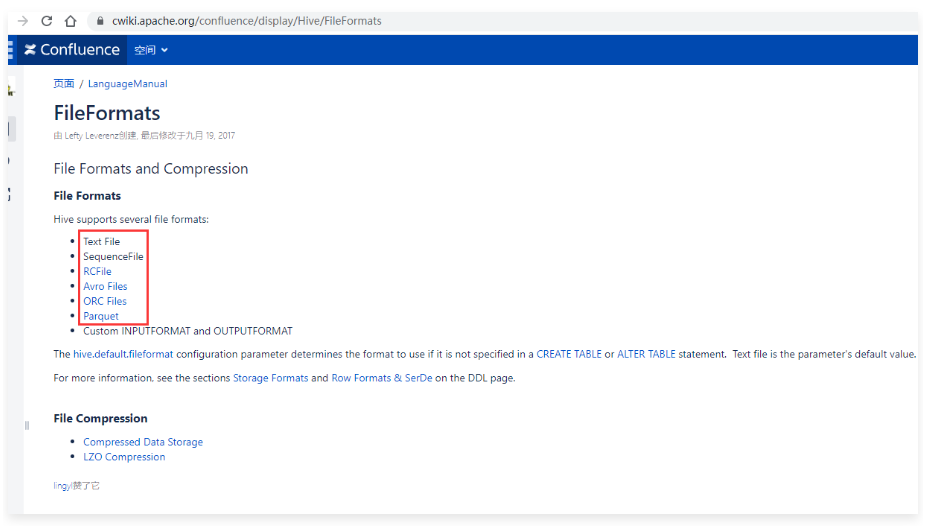
1 | 目前工作中使用最多的是TextFile、ORC和Parquet。 |
数据存储格式之TextFile 2.09g
1 | TextFile是Hive的默认数据存储格式,基于行存储。 |
1 | create external table stu_textfile( |
1 | 然后生成测试数据,并把测试数据加载到这个表中。 |
1 | 将这个数据文件上传到Hive表stu_textfile对应的hdfs目录中。 |
使用Defalte压缩格式 388m
1 | 接下来基于stu_textfile这个普通数据表构建一个新的压缩数据表。 |
1 | create external table stu_textfile_deflate_compress( |
1 | Hive中默认是没有开启压缩的,想要开启压缩需要使用下面这条命令: |
1 | 接下来通过insert into select从普通表中查询数据,插入到压缩表中。 |
1 | 最终产生的结果数据是这样的: |
1 | 在这里发现这个SQL最终只生成了1个Map任务,也就意味着这个388M的文件是有一个Map任务负责计算。 |
使用Bzip2压缩格式 189m
1 | 再来验证一下Bzip2压缩格式。 |
1 | 从普通表中查询数据插入到压缩表中。 |
1 | 结果发现只产生了1个Map任务,正常情况下这份数据会被切分成2个Split,产生2个Map任务的,为什么这里只有1个Map任务呢? |
1 | CombineHiveInputFormat中在切分Split的时候会参考mapred.max.split.size参数的值。 |
1 | 这个时候发现产生了2个Map任务,最终可以确认,在Hive中Bzip2压缩文件也是支持切分的。 |
数据存储格式之SequenceFile
1 | 下面我们来看一下SequenceFile这种存储格式 |
不使用压缩 2.7g
1 | 先不使用压缩,创建一个SequenceFile存储格式的表。 |
1 | 如果INPUTFORMAT使用的是SequenceFileInputFormat,说明这个表中需要存储SequenceFile格式的数据。 |
1 | 注意:这个文件在2.7G左右,比原始的TextFile文件还要大,原始的TextFile文件才2.09G。 |
1 | 可以看到产生了11个map任务,说明SequenceFile格式的文件支持切分。 |
1 | package com.imooc.compress; |
1 | 执行代码,可以看到这样的结果: |
使用Deflate压缩(Block级别) 2.39g
1 | 接下来使用Deflate压缩试验一下,基于Block压缩级别 |
1 | 压缩之后的数据小一些,2.39G。 |
1 | 这个怎么理解呢? |
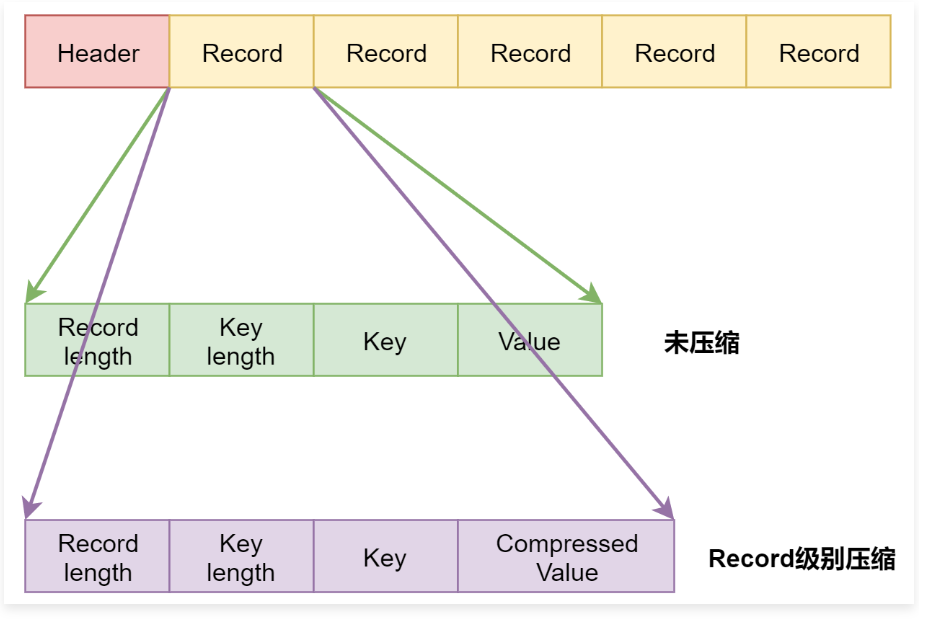
1 | 上面表示是SequenceFile中的数据,每一个Record代表里面的一条数据。 |
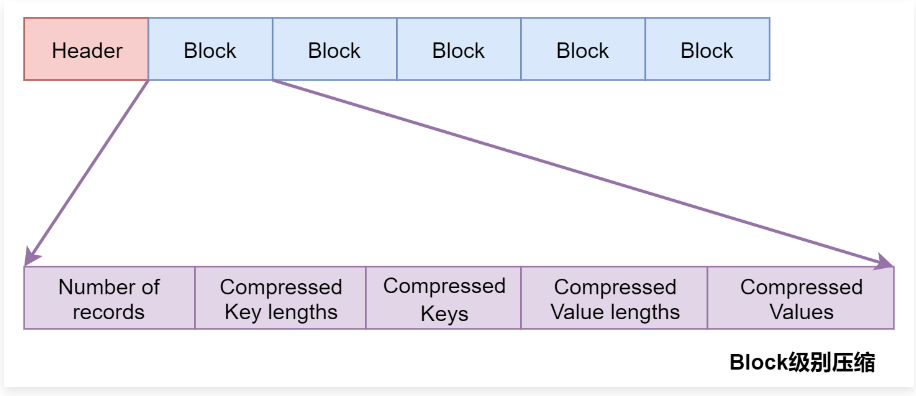
1 | 当使用Block级别压缩的时候,SequenceFile中的数据是以Block为单位存储的,每个Block中存储多个Record,并且对Block内部的多个Record统一压缩存储。 |
数据存储格式之RCFile
不使用压缩 1.6g
1 | create external table stu_rcfile_none_compress( |
使用Deflate压缩 382m
1 | create external table stu_rcfile_deflate_compress( |
1 | 指定使用deflate压缩。 |
数据存储格式之ORC
不使用压缩 1.38g
1 | create external table stu_orc_none_compress( |
使用Zlib压缩 269m
1 | create external table stu_orc_zlib_compress( |
使用Snappy压缩 529m
1 | create external table stu_orc_snappy_compress( |
数据存储格式之PARQUET
不使用压缩 2.05g
1 | create external table stu_parquet_none_compress( |
使用Gzip压缩 358m
1 | create external table stu_parquet_gzip_compress( |
使用Snappy压缩 804m
1 | create external table stu_parquet_snappy_compress( |









